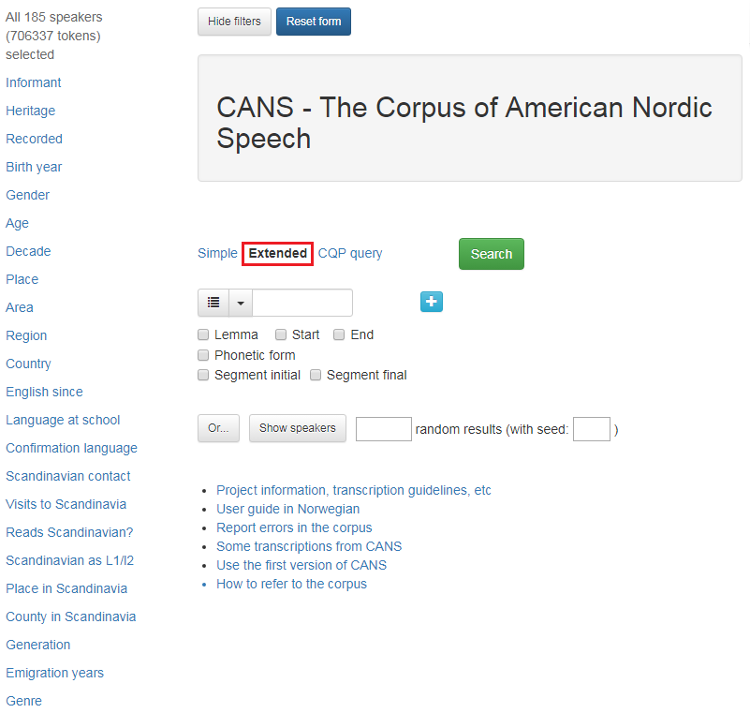
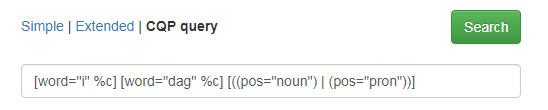
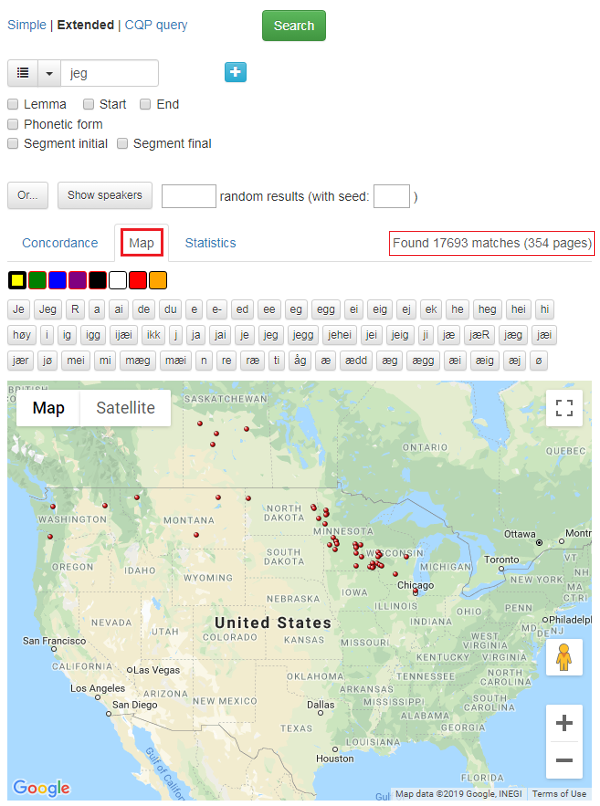
Figure 1 shows the main search page of CANS:
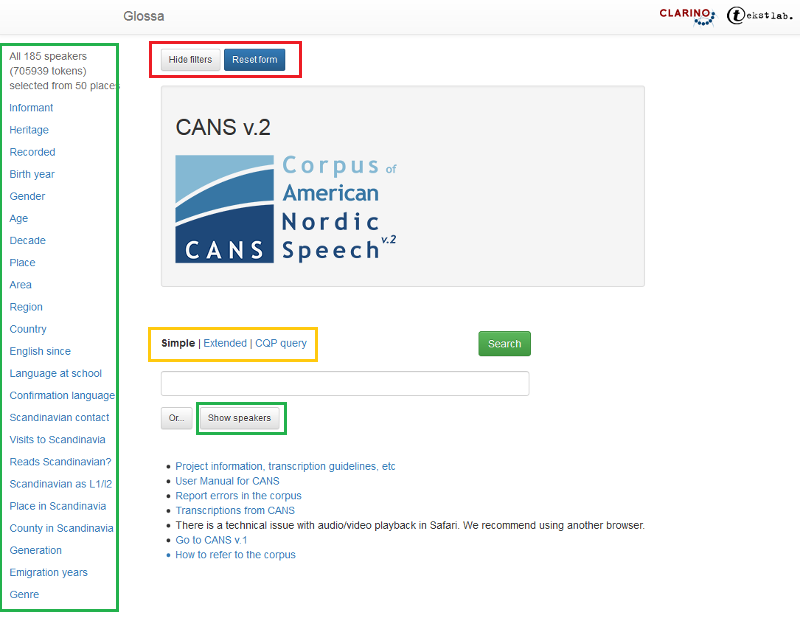
Figure 1: Main search page of CANS.
User Manual for CANS - Corpus of American Nordic Speech
This user manual is written by Kristin Hagen and Ingvild Røsok. The manual is based on The Nordic Dialect Corpus - Search Interface Documentation written by Eirik Olsen.
1. CANS - Corpus of American Nordic Speech v.2
CANS consists of interviews and conversations with 163 Norwegian American informants from 44 places in the USA and Canada, as well as 22 Swedish American informants from 7 locations in the USA. The recordings are transcribed and linked to audio and video. The corpus has a map function, and can be searched in a variety of ways.
On this page:
1.1 Transcriptions in CANS
1.2 Main search page of CANS
1.2.1 Simple search and examples of results
1.2.2 Extended search
1.2.2.1 Search multiple words
1.2.2.2 Search Lemma, Start, End, Segment initial, Segment final or Phonetic
1.2.2.3 Search for word class or morphological features
1.2.2.4 Search different tags (laughter, words not in the dictionary, etc.)
1.2.2.5 Specify or exclude Lemma or Word form
1.2.3 CQP Search Expression (CQP query)
1.2.4 'Or' search
1.3 Metadata search and Show speakers
1.4 Random selection of search results
1.5 Geographical Map
1.6 Statistics
1.7 Download data
1.1 Transcriptions in CANS
The recordings of CANS have been transcribed orthographically and phonetically by using the transciption program Transcriber, and later on the transcription program Elan.
The interviews and conversations in the corpus are transcribed in two ways: a phonetic transcription and an orthographic transcription. The transcriptions are connected to each other and to the original audio and video files.
You can read about the transcription manuals for Norwegian and Swedish on this page.
1.2 Main search page of CANS
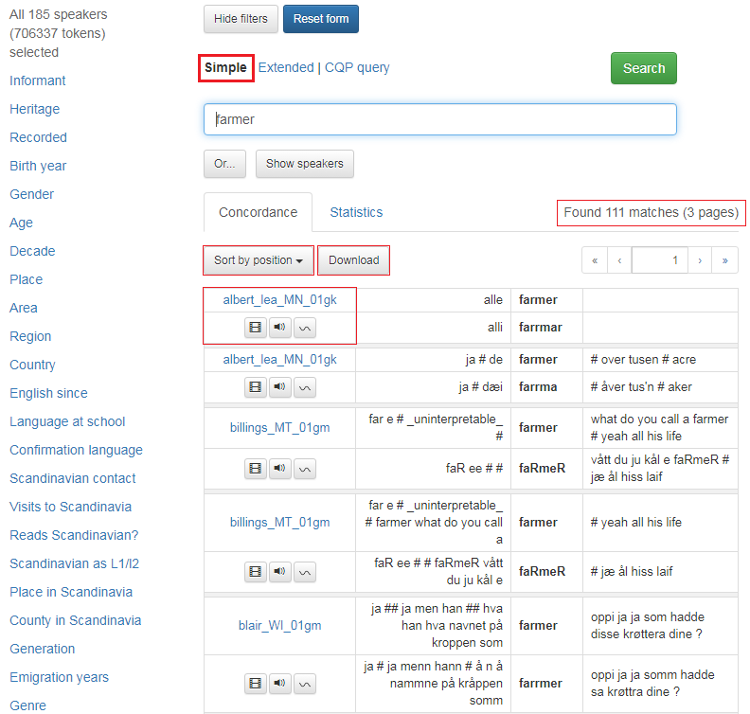
Figure 1 shows the main search page of CANS:
Figure 1: Main search page of CANS.
To the left in the green frame are all the searchable metadata categories. In CANS, these categories are a selection of different features relating to the informants including, Informant, Heritage, Recorded, Birth year, Gender, Age, Decade, Place, Area, Region, Country, English since, Language at school, Confirmation language, Scandinavian contact, Visits to Scandinavia, Reads Scandinavian?, Scandinavian as L1/l2, Place in Scandinavia, County in Scandinavia, Generation, Emigration years, Genre.
The number of selected informants (including the number of tokens) and number of locations are indicated above the meta-categories. The Show speakers button gives you an overview of all the informants or the selection of informants you have chosen. Read more in section1.3.
At the top of the page, you will find two buttons. The Hide filters button hides the metadata tabs to the left, while the Reset form button gives you a blank search page. The rest of the search page is about the searched keyword(s) or its properties. You can read more below.
1.2.1 Simple search and examples of results
In Simple search you can search for individual words and phrases in the search field.
The results are shown as a concordance (see figure 2). The number of matches can be seen above the search results on the right. There are 50 search results presented per page. If there are more than 50, they will be presented across multiple pages, which you can access by clicking the arrows, see figure 2.
Above the search results you will find buttons for sorting and downloading. For more information, see section 1.7. and 1.8. The Concordance search result view is the pre-selected view but you can also get different statistical views of the search result (see section 1.6) or view the results on a geographical map, (see section 1.5.)
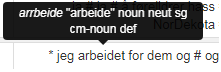
If you hover your mouse over a word from the search result, a small window will pop up with information about lemma, word class, other morphological information and tags (see figure 3). Read more about word class and tags in sections 1.2.2.3 and 1.2.2.4.
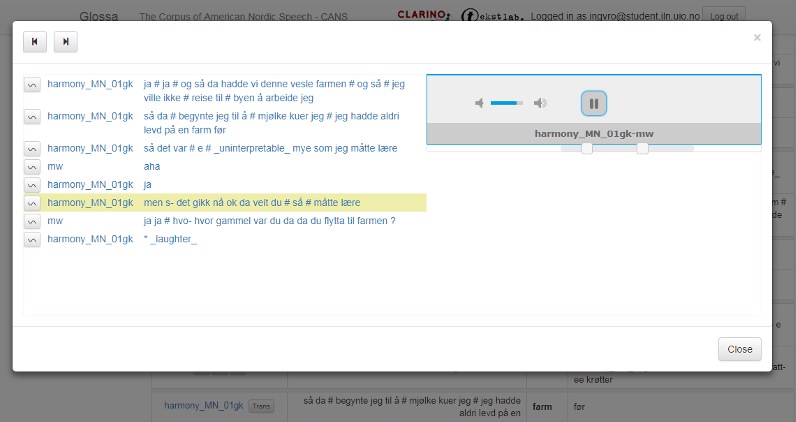
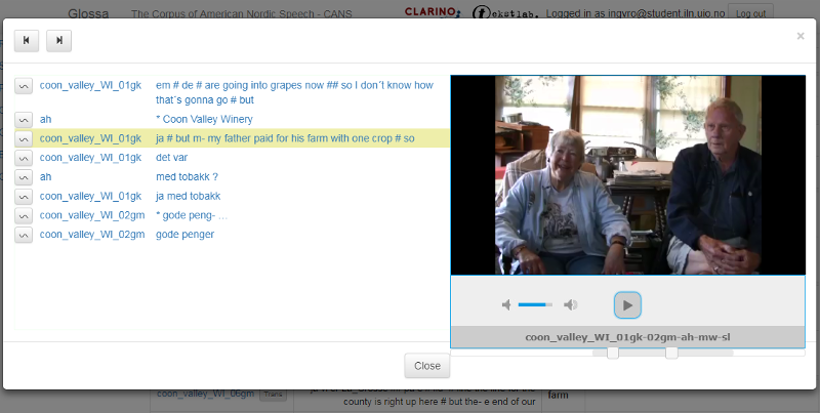
In the left-hand column of the search results there are three icons. Click on the video icon (first icon) to watch a video of the search result (see figure 5). Be aware that not all recordings have the video possibility. Click the audio icon (second icon) to get audio only (see figure 4). Within the audio and video media player, more context can be accessed by moving the square buttons on the slider bar, located below the box, to the left and / or right.
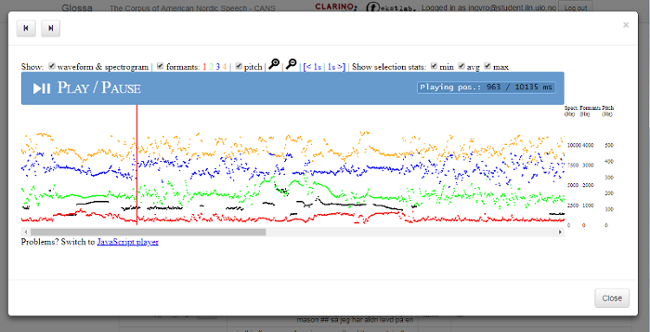
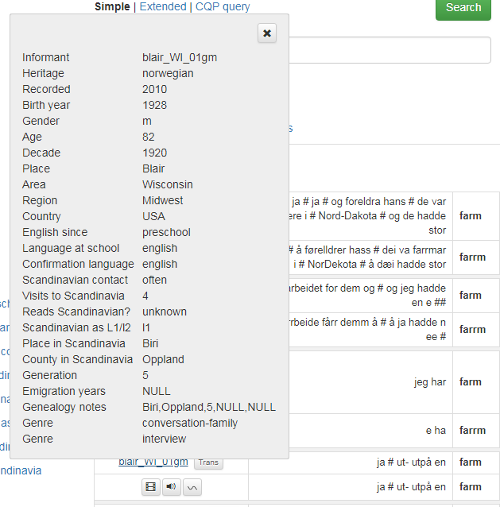
Click on the third icon to view a sound wave and spectrogram of the search result (see figure 6). Click on the informant code to view the metadata about the informant (see figure 7).
The orthographic transcription is placed above the original phonetic CANS trancription in the search results.
Figure 2: Search results for individual words in the corpus
Figure 3: If you hover the mouse over a word from the search result, a small window will be displayed with information about word class, other morphological information and tags. It will also contain the phonetic transcription, if it exists
Figure 4: Audio playback of the search result
Figure 5: Video playback of the search result
Figure 6: Sound wave and spectrogram
Figure 7: Metadata about the informant
1.2.2 Extended search
An extended search (see figure 8) provides you with more search options. You can search both individual words and phrases, on lemma, start or end of words, or the beginning or end of a segment (segment initial / segment final). The phonetic option gives you the opportunity to search in the semi-phonetic part of the transcription only. Furthermore, you can do a search on word classes, morphological features or other tags.
1.2.2.1 Search multiple words
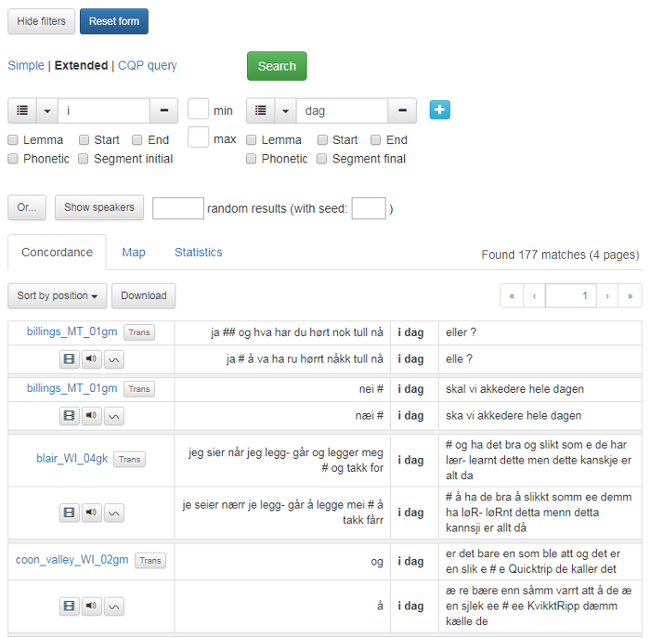
If you click on the blue plus sign to the right of the search box (see figure 9), a second search box will pop up. You can create as many search boxes as you like. Between the search boxes, you will find two boxes labeled min and max that you can use to define the minimum or maximum word limit you want between keywords. To remove a search box, click the grey minus sign on the right-hand side of the box.
Figure 9 shows a search for the phrase i dag (today). Note that there are 177 matches presented over 4 pages. Click the arrows to navigate the search results.
Figure 9: Search multiple words.
1.2.2.2 Search Lemma, Start, End, Segment initial, Segment final or Phonetic
Below the search window there are six boxes that you can select by ticking: Lemma, Start, End, Phonetic, Segment initial or Segment final. If you tick the box Lemma, you get all the inflectional forms of a word as a result. If you search for the word bok (book), you get all the forms (bok, boka, boken, bøker and bøkene) as a result if the words exist in the corpus. If you tick Start or End, you will get all the words that begin with the word or letters that are typed in the search box. A search for bok where the Start box is ticked can give results like bokklubb (book club) or bokstaver (letters). If the End box is ticked, the results may be words like a lesebok (reading book) or baseballbok (baseball book).
By default, any text entered in the search box will be searched for in the orthographic transcription part of the corpus. The transcriptions also have alternative transcriptions in addition to the orthographic ones, and these transcriptions may be queried by ticking the Phonetic box. This may be helpful, for instance, if you look for specific phonetic variants in Norwegian like itte or ikkje, variants for the orthographic ikke (not).
In figure 2, the word farmer is in some cases pronounced faRmeR. If you do a search for the word faRmeR and tick the Phonetic box, you will get 5 matches. You can search both the phonetic and the orthografic version at the same time. Read more about this in section 1.2.2.5.
The transcriptions in CANS consist of segments, not sentences in a written language sense. The segments are separated from each other, not by punctuation, but with time codes that indicate where in the video or audio file the segment starts or stops. The segments will often match written language sentences, but since this is speech, there may also be incomplete sentences without subject and verbal.
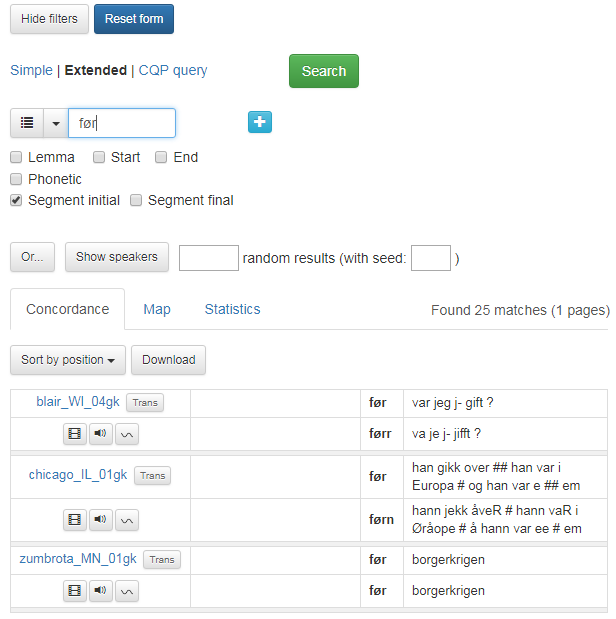
If you select Segment initial, you specify that the search term must come first in a segment. Ticking the Segment final box means doing a search for the last word. Figure 10 shows a search for the word før (before) in Segment initial position.
Figure 10: Før in Segment initial position.
1.2.2.3 Search for word class or morphological features
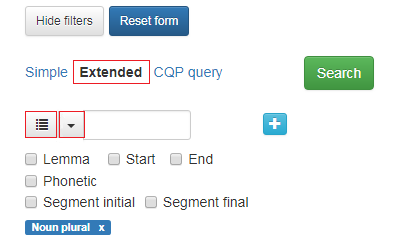
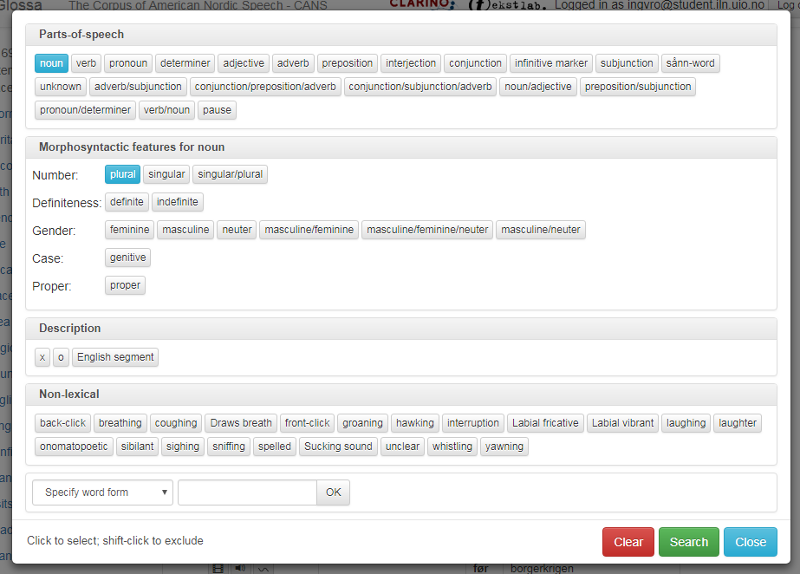
In an extended search, you can search for word class by clicking the arrow on the left-hand side of the search box, see figure 11.This will give you a drop down menu with various word class options. Clicking the button to the left of the arrow opens a box that gives an overview over both word class options and morphological features, see figure 12. If you select a word class under Parts-of-speech, you also get access to the options under Morphosyntactic features for the word class you have chosen. Your selections will appear as small blue boxes. Figure 11 shows a search for noun plural.
The other options in figure 12 are explained in the chapters below.
Figure 11: Buttons for searching word class and other morphological features
Figure 12: Searching for word class and other morphological information
If you click on multiple word classes simultaneously, such as noun and pronoun, you will get all the words that are either nouns or pronouns. Correspondingly, you can click multiple values within a category, such as both feminine and masculine in the gender category for nouns to find words that are either feminine, masculine or both.
1.2.2.4 Search different tags (laughter, words not in the dictionary, etc.)
Under the categories description and non-lexical, as described in section 1.2.2.3 above (figure 12), you can search for tags that either describe a word or that are independent events in speech, such as coughing or laughing for instance.
In the Description category of the search box you can search for the follwing three tags:
X: The recordings have been transcribed orthographically using Bokmålsordboka (2005) as a guideline. The x-tag has been used in segments where the primary language is Norwegian, but has instances of English words or words that are not in the dictionary.
O: The o-tag has been used in instances where grammatical words that aren't found in the orthographic standard are "translated" to their standard equivalent.
English segment: This refers to an English sequence, where multiple words were uttered in English.
If you tick one or more of the tags above, you will get the connected words as a result.
In the Non-lexical category of the search box you can apply the following tags:
back-click, breathing, coughing, draws breath, front-click, groaning, hawking, interruption, labial fricative, labial vibrant, laughing, laughter, onomatopoetic, sibilant, sighing, sniffing, spelled, sucking sound, unclear, whistling and yawning.
These are independent events within the speech. Most of the tags are sounds or non-lexical utterances such as laughter and coughing.
Interruption is applied whenever an informant interrupts himself / herself or is interrupted by the interviewer or another informant.
Unclear is applied for words that are unclear or otherwise uncertain for the transcribers who worked with the transcriptions.
Spelled refers to words that are spelled out by the speaker.
Laughing refers to words uttered while laughing, while laughter refers to the non-lexical sounds of laughter.
Singing / yawning are words that are uttered while the informant is singing or yawning.
The X, O and English segment tags and the non-lexical tags are associated with one or more words. If you tick one or more of the tags, you will get the words that are linked to them as a result.
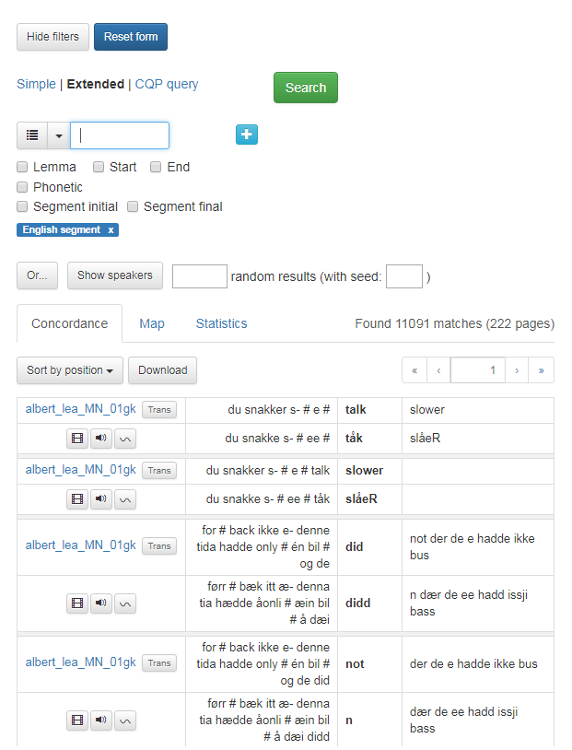
In figure 13 there has been a search for words tagged with english for English segment. Note that because the search view shows one word in bold text at the time, and not the whole segment, it could be useful to use the audio function to get an overview of the context and the segment as a whole.
Figure 13: Search words tagged with english for English segment
1.2.2.5 Specify or exclude Lemma or Word form
At the bottom of the morphological search box in figure 12 there is a field where you can further specify a search (box labeled Specify word form). So, if you want to search for verb in the morphological search box, but are only looking for auxiliaries, you can simply select Specify lemma and add the auxiliaries one by one in the Specify word form box, pressing OK after each word.
If you have chosen verb, but do not wish to include the auxiliaries, you can follow the same procedure as above, but use the arrow in the Specify word form box to select a different option from the drop down menu. Choose Exclude word form or Exclude lemma.
If you have done a search using Phonetic, as described in section 1.2.2.2, you can specify what orthographic word form and lemma you are looking for by selecting Specify word form or lemma. So if you select Phonetic and type je and select Specify word form and search jeg, you will get all instances where jeg is pronounced je as a result.
NB! Remember to click the OK button when you have added a word. Words that are excluded will appear in red with an exclamation point to the right of the box (see figure 14 and figure 16). Words that are specified, will appear in blue.
Figure 14: Specify or exclude Lemma or Word form.
1.2.3 CQP Search Expression (CQP query)
CQP queries can be used for advanced searches that are not possible in simple or extended searches. To use this option, you will need to be familiar with the CQP query language. If you need help with an advanced search, you can contact the Text Laboratory. Figure 15 shows an example of how searches for the words i dag (today) followed by noun or pronoun appear in either Extended search and CQP query. If you have used the options in Extended search and wonder how this search looks in the CQP search language, click CQP query to get the search expression as seen in figure 15.
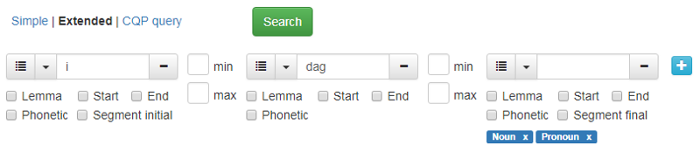
Figure 15: Example of same search in Extended search and CQP query
1.2.4 'Or' search
Clicking on the Or box will open a new search window below the original one. Searches in this box provides an Or search. That is, you search the word in the main box or in the Or box. You can create as many Or boxes as you want. You delete them by clicking the red cross to the left of the box.
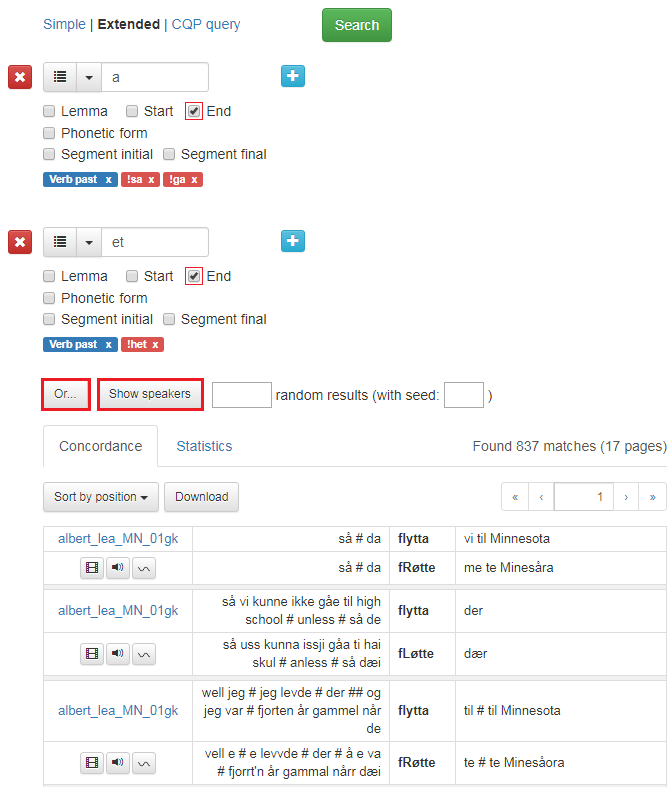
Figure 16 shows an advanced search for verbs in past tense that end with either -a or -et. The verbs sa (said), het (was called) and ga (gave) are excluded.
Figure 16: 'Or' search
1.3 Metadata search and Show speakers
As shown earlier in figure 1, all the meta-categories in the search form are listed in a column to the left of the search form. In CANS, these categories are as follows: Informant, Heritage, Recorded, Birth year, Gender, Age, Decade, Place, Area, Region, Country, English since, Language at school, Confirmation language, Scandianivan contact, Visits to Scandinavia, Reads Scandinavian?, Scandinavian as L1/l2, Place in Scandinavia, County in Scandinavia, Generation, Emigration years, Genre.
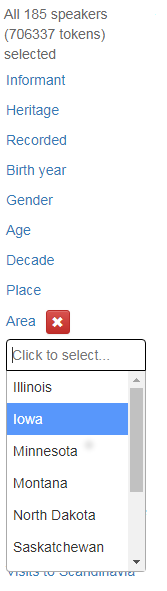
Clicking on one of the links will bring up the different values in each category. You can click and select one or more, and the results of your choice will be displayed in a box below the category. If you click on the red cross sign, the choice will be reset. Figure 17 shows what the metadata menu looks like when you click on the Area category.
Figure 17: Metadata menu, where the chosen category is Area.
The choice you make restricts the options for further searches. For example, if you choose F in the Gender category, you will only be able to select values that are associated with the female informants. Therefore, you will not get Iowa under Area because there are only male informants from this area in the corpus.
In figure 18, Illinois has been chosen under Area. There are both female and male informants from this area.
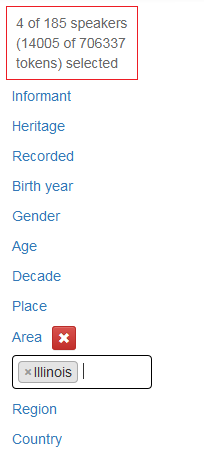
Figure 18: Illinois is selected under Area
Above the metadata category menu, there is a counter that shows you how many informants you have chosen, and how many tokens the selection consists of at any time. In this version, CANS contains 185 informants and 706 337 tokens (words and punctuations), as shown in the figures above. When only informants from Illinois are chosen, the selection will be confined to 4 speakers and 14 005 tokens, as shown in figure 18.
If you want to see an overview of the informants you have selected, click the Show speakers button next to the Or button (see figure 16). The result will be presented as in figure 19 based on the selection from figure 18.
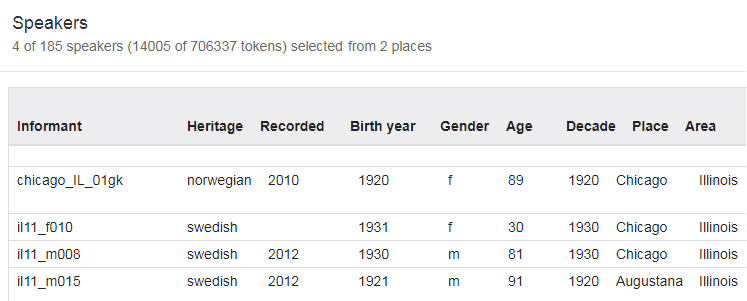
Figure 19: The Show speakers window
The different meta-categories are briefly described below:
Informant: Each informant has been given an informant code instead of their real name. This code consists of place name, state (postal code), a number and the abriviation gk, gm for gammel kvinne / mann (elder woman / man) or uk, um for ung kvinne / mann (younger woman / man). You can search for one or multiple informant codes.
Heritage: Gives details about the informant's heritage. Choose between Norwegian or Swedish
Recorded: Provides the year the audio was recorded
Age, Birth year and Gender: Gives details about the informant's age, birth year and gender
Decade: Indicates in which decade the informant was born
Place: Provides the town / place the informant is from
Area: Provides the state or province the informant is from.
Region: Provides the region the informant is from
Country: Indicates the country the informant is from. Choose between the USA and Canada
English since: Indicates when the informant learned to speak English
Language at school: Language the informant used at school
Confirmation language: Language(s) spoken at the informant's confirmation
Scandinavian contact: Gives details about the infromants' contact with Scandinavia
Visits to Scandinavia: Indicates the number of visits to Scandinavia
Reads Scandinavian?: Indicates the informant's ability to read Scandinavian
Scandinavian as L1/l2: Indicates whether Scandinavian is a first or second language
Place in Scandinavia: Indicates the place in Scandinacia where the informant's ancestors or family are from
County in Scandinavia: Indicates the county (fylke/len) the informant's ancestors or family are from
Generation: Provides the number of generations since the first Scandinavian ancestor (or the informant) immigrated
Emigration years: Indicates when the informant or the informants' ancestor(s) emigrated
Genre: Indicates whether it is an interview or conversation
You can read more about the informants on the CANS homepage.
1.4 Random selection of search results
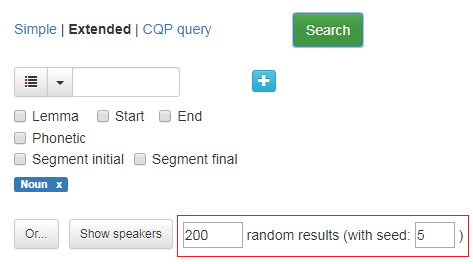
If you have a search that will give numerous hits, you can choose to view only a certain number of randomly selected hits. Specify the number of hits in the box next to Show speakers (see figure 20).
If you want to reproduce this specific result later, select a number and insert it into the box called with seed. In figure 20, the search is extended to all nouns in the corpus, with 200 randomly selected hits showing at a time, and the number 5 in the with seed box. Each time you do the same search and type the same number in the box, you get the same random selection of search results. If you type another number, you will get another random selection.
It is possible to select a random selection of search results for searches that are Extended searches or CQP queries.
Figure 20: Checkbox that gives a random selection of search results. Here shown with 200 possible results.
1.5 Geographical map
The Concordance view is the pre-selected search result and all the above examples are taken from here. If you select Map, as shown in figure 21 below, you can get an overview of the distribution of a word and its variants in the corpus. You can zoom in and out of the map to get a better overview.
Figure 21: Map showing variants of a search word and where they are found
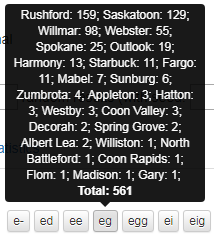
By hovering the mouse over a variant, as shown in figure 22, you get a window with details about the locations where the variant is used, the number of times it is used in each location, and the number of hits for the variant total. The number of hits for all variants combined can be found in the upper right-hand cornerabove the map under Found (see figure 21 or figure 23).
Figure 22: The distribution of a word's variants and the number recorded at each location
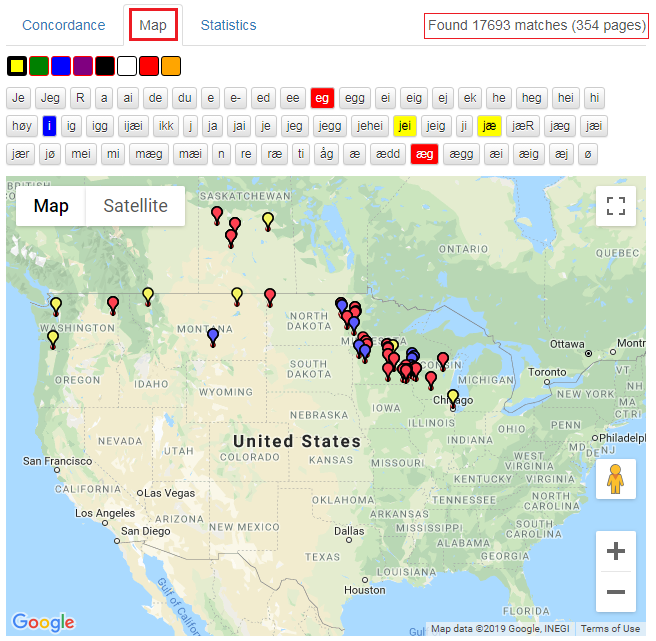
By clicking on a color and then on a variant, you can see the distribution of the chosen variant on the map. In figure 23 below, three of the variants are marked with the colors yellow, red and blue. To remove the color, click the box once or twice until the box color returns to grey.
Figure 23: Use the colors to see the distributions of the variants.
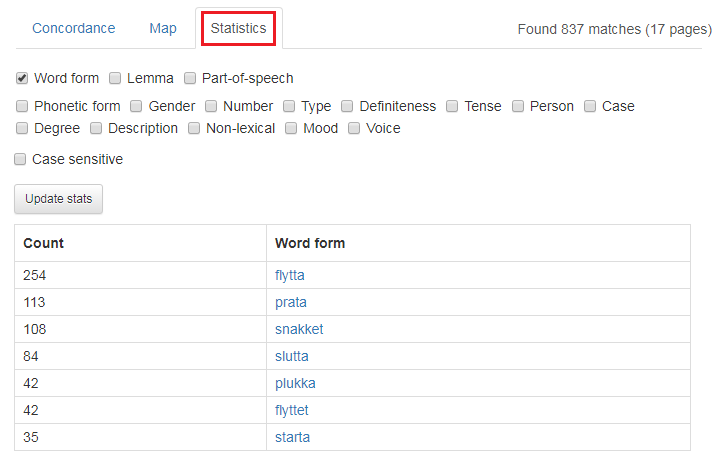
1.6 Statistics
The search result view Concordance is the default and from which all the examples above are taken from. If you select Statistics as shown in figure 24 below, you can see different frequency counts and statistics. Currently, the boxes above the Update stats button are the ones that can be selected. Click on what you want to see and press Update stats. Figure 24 displays frequencies from the search results shown in figure 16, which showed a search for verbs in past tense that end with either -a or -et. The verbs sa (said), het (was called) and ga (gave) are excluded. In figure 24, the frequencies are listed in the left-hand column, and the word forms are listed to the right.
Figure 24: Statistical display for the results shown in figure 16
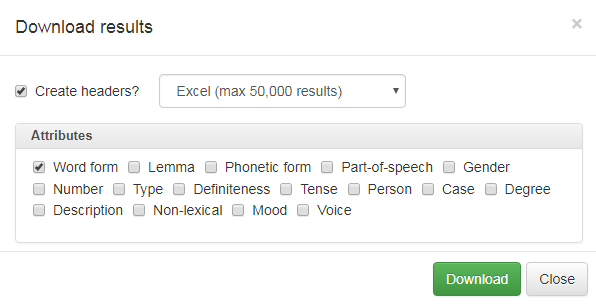
1.7 Download data
If you click on the Download button above the search results (see figure 2), a dialogue box will pop up where you can choose multiple download formats such as: Excel, tab-separated or comma-separated text file. You can also choose which information to download (see figure 25).
Figure 25: Download options window
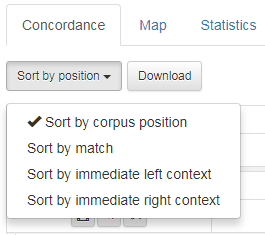
1.8 Sort the search results
The search results can be sorted in various ways as shown in figure 26. If you want to sort by search word, select Sort by match. You can also sort by the word directly to the left (sort by immediate left context) or the word directly to the right (sort by immediate right context). Note that punctuation marks are alphabetized before a and b, etc (see figure 27).
Figure 26: Search results can be sorted in different ways
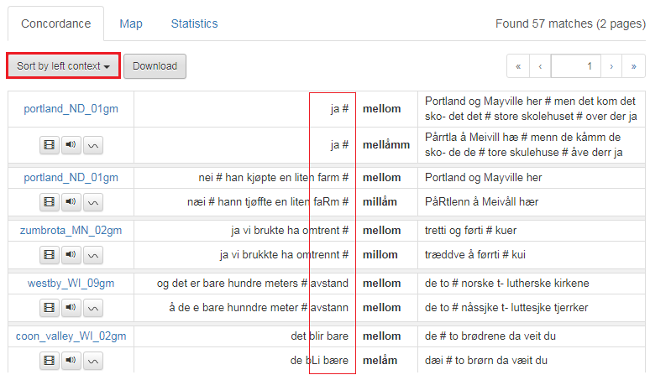
Figure 27: Punctuation marks or symbols are alphabetized before a and b.