![]()
Brukerveiledning for NORMKORPUSET
Oversikt over oppgaveformuleringene i Norm-materialet
Normkorpuset har fått nytt søkegrensesnitt: https://tekstlab.uio.no/glossa3/norm
Denne nye versjonen av søkegrensesnittet
Glossa er i hovedsak lik den gamle, men har noen nye funksjoner.
Se hvordan du kan bruke den nye versjonen av Glossa i to instruksjonsvideoer:
Denne brukerveiledningen er skrevet for den gamle versjonen av søkegrensesnittet: https://tekstlab.uio.no/glossa2/norm
Kontakt tekstlab-post@iln.uio.no om du har spørsmål.
Brukerveiledningen er skrevet av Kristin Hagen, Synnøve Matre, Hildegunn Otnes og Randi Solheim.
Innhold
2.2 Prosjektskolene og kontrollskolene
2.3 Elevgruppene
2.4 Hvor mange tekster har elevene skrevet?
2.5 Navn på skolene
2.6 Målform
2.7 Fordeling av elever og tekster
3.1 Hvordan forstå tekstkoden
3.1.1 Skolekode
3.1.2 Elevens trinn ved prosjektstart
3.1.3 Elevnummer
3.1.4 Kjønn
3.1.5 Førstespråk
3.1.6 Elevens trinn da teksten ble skrevet
3.1.7 Skrivehandling
3.1.8 Versjon
3.1.9 Datatype
3.1.10 Tekstnummer
3.1.11 Hva kan vi lese ut av tekstkoden?
4.1 Søkesiden
4.1.1 Valg av tekster
4.1.2 Enkelt søk («Simple»)
4.2 Utvidet søk («Extended»)
4.2.1 Søke etter enkeltord
4.2.2 Søke etter flere ord
4.2.3 Søk på 'Lemma', 'Start', 'End', 'Original', 'Sentence initial' eller 'Sentence final'
4.2.4 Original
4.2.5 Ordklasse ('Part of speech') og/eller morfologiske trekk
4.2.6 Søk på andre tagger (særskriving mfl.)
4.2.7 Spesifiser eller ekskluder lemma og ordform
4.3 Andre muligheter
4.3.1.CQP-søkeuttrykk (CQP query)
4.3.2.Eller-søk ('Or')
Normkorpuset består av autentiske elevtekster skrevet innenfor ulike skolefag på barne- og mellomtrinnet. Korpuset rommer rundt 5 200 tekster av ulik lengde. Tekstene er skrevet ut fra oppgaver med eksplisitte føringer om formål og skrivehandling – planlagt inn i pågående tema/arbeid i de ulike fagene. En del av tekstene finnes i to versjoner – ett utkast og en versjon bearbeidet etter tilbakemelding.
Tekstene er samlet inn ved 24 skoler rundt om i landet og inkluderer både by og land og skoler med nynorsk og bokmål som hovedmål. Skriverne er både elever med norsk som førstespråk og minoritetsspråklige elever med norsk som sitt andrespråk. Tekstene er samlet inn i perioden 2012–2014.
Tekstene finnes i tre utgaver: elevens skannete originaltekst med eventuelle tegninger, tabeller o.l., samt to transkriberte varianter, der den ene er slik eleven har skrevet den, den andre i en korrigert bokmåls- eller nynorskversjon, som er tagget (se 3.3). De to transkriberte versjonene er koblet sammen i korpuset.
Tekstene er skrevet innenfor forskningsprosjektet Developing national standards for the assessment of writing. A tool for teaching and learning («Normprosjektet»), en stor intervensjonsstudie om skriving som grunnleggende ferdighet og vurdering av skriving i norsk skole. Prosjektets mål har vært å utvikle og prøve ut eksplisitte forventningsnormer til bruk i skriveopplæring og vurdering, og å undersøke hvordan disse kan påvirke elevenes skrivekompetanse og lærernes vurderingspraksis. Hoveddelen av prosjektet ble gjennomført som intervensjoner ved prosjektskolene, der lærerne fikk hjelp til å integrere et funksjonelt syn på skriving og vurdering og en felles forståelse av dette feltet.
Se mer informasjon på prosjektets nettsider og i oversiktsartikkelen Forventninger om skrivekompetanse.
2.2 Om prosjektskolene og kontrollskolene
I Normprosjektet har 20 prosjektskoler og 4 kontrollskoler levert inn tekster som inngår i korpuset. Man kan gjenkjenne hvilken type skole eleven tilhører ved å se på tekstkoden til besvarelsene i korpuset (jf. 3.1).
Tekstene som elevene fra prosjektskolene har skrevet, har en tekstkode som inneholder en bokstav fra «a-t» der skolekoden er markert (jf. 3.1.1). Tekstene fra kontrollskolene vil ha en skolekode merket med én av bokstavene «v, w, y, z».
Skolene som deltok i Normprosjektet var fordelt over fire trinn da prosjektet startet høsten 2012: 3. trinn, 4. trinn, 6. trinn og 7. trinn.
Elevene som gikk på 3. trinn (300-elever) og 6. trinn (600-elever) ved prosjektstart, ble fulgt over to skoleår: skoleåret 2012/2013 og skoleåret 2013/2014.
Elevene som gikk på 4. trinn (400-elever) og 7. trinn (700-elever) ved prosjektstart, ble fulgt over ett skoleår: skoleåret 2012/2013.
Vi omtaler altså elevgruppene ut fra hvilket trinn de var på da prosjektet startet, og tekstene er nummerert ut i fra dette (jf. 3.1):
2.4 Hvor mange tekster har elevene skrevet?
Totalt i prosjektet ble det samlet inn ca. 50 000 tekster. I korpuset inngår både tekster fra prosjektskoler og kontrollskoler, og fra elever som ble fulgt over ett og to år. Det gjør at de ulike elevgruppene har skrevet ulikt antall tekster.
De 5 200 tekstene i Normkorpuset utgjør et utvalg av disse tekstene, nærmere bestemt alle tekster fra hver 11. elev ved prosjektskolene og inngangs- og utgangstekster fra kontrollskolene.
Elevene fra prosjektskolene som ble fulgt over ett år i prosjektet (400- og 700-elevene) skrev disse ni tekstene (i korpus-menyen omtalt som datatype):
Elevene fra prosjektskolene som ble fulgt over to år i prosjektet (300- og 600-elevene) skrev disse 15 tekstene:
Elevene fra kontrollskolene skrev bare inngangs- og utgangstekster:
For disse skolene er ikke utvalget avgrenset. Her er således inngangs- og utgangstekstene til alle elevene med.
Dekknavnene til skolene er gitt ut i fra hvilken bokstavkode hver enkelt skole fikk (jf. 3.1.1). Bokstavkode og dekknavn er som følger:
Bokstavkodene for kontrollskolene: v, w, y, z
Skolene har denne fordelingen ut fra målform:
2.7 Fordeling av elever og tekster
Normkorpuset består totalt av 5196 tekster skrevet av 612 elever.
Tabell 1 viser fordelingen av elevene ut fra trinn og om de er fra en prosjektskole eller kontrollskole.
| Elevkode | Antall elever fra prosjektskoler | Antall elever fra kontrollskoler | Antall elever totalt |
| 300-elever | 97 | 67 | 164 |
| 400-elever | 85 | 73 | 158 |
| 600-elever | 97 | 67 | 164 |
| 700-elever | 100 | 26 | 126 |
| Totalt | 379 | 233 | 612 |
Tabell 1: Fordeling av elevene i prosjektet
Tabell 2 viser hvor mange tekster som er skrevet på hver skole fordelt på trinn.
| Skole | Antall tekster av 300-elever | Antall tekster av 400-elever | Antall tekster av 600-elever | Antall tekster av 700-elever | Antall tekster til sammen |
| a | 210 | 112 | 197 | 120 | 639 |
| b | 131 | 27 | 72 | 38 | 268 |
| c | 97 | 0 Merk! | 116 | 44 | 257 |
| d | 14 | 44 | 38 | 56 | 152 |
| e | 205 | 94 | 126 | 104 | 529 |
| f | 38 | 19 | 32 | 15 | 104 |
| g | 28 | 9 | 33 | 11 | 81 |
| h | 33 | 38 | 31 | 63 | 165 |
| i | 32 | 18 | 52 | 29 | 131 |
| j | 88 | 43 | 113 | 72 | 316 |
| k | 61 | 17 | 42 | 27 | 147 |
| l | 100 | 64 | 105 | 41 | 310 |
| m | 77 | 24 | 72 | 16 | 189 |
| n | 84 | 38 | 90 | 15 | 227 |
| o | 36 | 8 | 51 | 30 | 125 |
| p | 64 | 38 | 84 | 39 | 225 |
| q | 27 | 39 | 31 | 27 | 124 |
| r | 34 | 17 | 32 | 16 | 99 |
| s | 122 | 48 | 78 | 34 | 282 |
| t | 86 | 37 | 91 | 43 | 257 |
| Totalt prosjektskoler | 1628 | 751 | 1528 | 867 | 4774 |
| v | 44 | 76 | 89 | 0 | 209 |
| w | 27 | 30 | 30 | 24 | 111 |
| y | 47 | 40 | 44 | 14 | 145 |
| z | 45 | 47 | 18 | 0 | 110 |
| Totalt kontrollskoler | 163 | 193 | 181 | 38 | 575 |
| Totalt alle skoler | 1730 | 927 | 1667 | 878 | 5202 |
Tabell 2 : Antall tekster fordelt på skole og trinn
Merk! Ingen 400-elever på Casa (c-skolen) ble valg ut til å levere tekster til Normkorpuset.
Vær også klar over at disse seks tekstene foreløpig ikke er lagt inn i korpuset på grunn av en feil: a645ga_7s2v_5, b328gn_3u2v_6, c354ja_3u0v_4, h724jb_7b0i_1, i309jn_3u0v_4, p602gn_6o0v_3.
Denne delen av brukerveiledninga viser hvilken informasjon man kan lese ut av tekstkoden (jf. 3.1): Skole, trinn, elevnummer, kjønn, førstespråk, år teksten er skrevet, skrivehandling, versjon, datatype, tekstnummer (i rekkefølgen av elevens tekster).
Vi gjør oppmerksom på at målform ikke inngår i tekstkoden. Den informasjonen ligger i bokstaven som indikerer skole (jf. 2.6).
I dette kapitlet står det også noe om tagging av tekster (jf. 3.3) og informasjon om hvordan tekstene er anonymisert (jf. 3.4).
Hver tekst i korpuset har en unik tekstkode. Koden er konstruert ut fra anonymiseringshensyn.
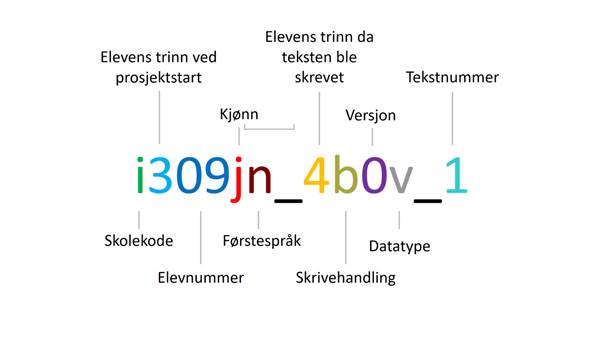
Tekstkoden består av 13 symboler, som er satt sammen av bokstaver, tall og tegn, og kan derfor fremstå som lite lesbar. Under får du en forklaring på hva de ulike symbolene i koden betyr. En tekstkode kan for eksempel se slik ut:
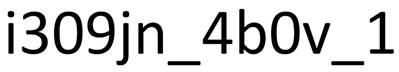
Figur 1: Eksempel på en tekstkode
Tekstkoden består av to deler: informasjon om eleven som har skrevet teksten og informasjon om selve teksten, se figur 2.
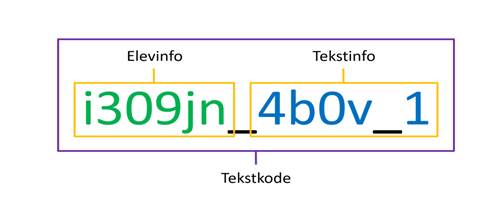
Figur 2 : Oppbygging av tekstkoden
Elevinformasjonen kan du bruke til å identifisere tekster skrevet av samme elev. Da vil for eksempel alle tekster skrevet av eleven i eksemplet over ha en tekstkode som starter med «i309jn». Elevinfoen vil derfor være lik for hver enkelt elev.
Tekstinformasjonen vil forandre seg for hver tekst en elev har skrevet. Elev i309jn har for eksempel skrevet både tekstene i309jn_4b0v_1 og i309jn_3r2v_5. Vi kan altså skille de ulike tekstene en elev har skrevet fra hverandre ved å se på tekstinformasjonen.
Går vi nærmere inn på hva de ulike symbolene i tekstkoden betyr, ser vi at den består av følgende deler, se figur 3:
Figur 3: Detaljert forklaring av tekstkoden
I det følgende forklarer vi de ulike tallene og bokstavene i tekstkoden i kronologisk rekkefølge.
Hver skole har sin individuelle skolekode bestående av én bokstav. Skolekoden har variablene «a-t» for prosjektskolene og «v, w, y, z» for kontrollskolene.
3.1.2 Elevens trinn ved prosjektstart
Dette tallet forteller hvilket trinn eleven gikk på da Normprosjektet startet. Tallet har variablene «3, 4, 6, 7», som står for 3. trinn (300-elever), 4. trinn (400-elever), 6. trinn (600-elever) og 7. trinn (700-elever) (jf. 2.3).
Elevnummeret består av et tosifret tall som er spesielt for den eleven på hans skole. Nummeret skiller eleven fra de andre elevene fra samme trinn på skolen.
Denne bokstaven forteller hvilket kjønn eleven har. Variablene er «g» gutt eller «j» jente.
Denne bokstaven beskriver hvilket språk eleven først lærte. Variablene er «n» for norsk, «a» for annet språk eller «b» for begge. Den siste koden finnes bare i noen få tilfeller, der eleven selv har krysset av for både norsk og annet språk.
3.1.6 Elevens trinn da teksten ble skrevet
Dette tallet forteller hvilket trinn eleven gikk på da den aktuelle teksten ble skrevet. Tallet har variablene «3, 4, 6, 7».
Om tekstene er skrevet i første innsamlingsår, vil dette tallet være likt tallet som indikerer elevens trinn ved prosjektstart, for eksempel i309jn_3r2v_5. Er teksten skrevet på andre innsamlingsår, vil teksten få et nummer høyere enn tallet som indikerer elevens trinn ved prosjektstart, for eksempel i309jn_4b0v_1.
Det betyr at alle 300-elevene både kan ha variablene «3» eller «4» i tekstinformasjonen, og 600-elevene kan ha «6» eller «7» (jf. figur 2), ut fra hvilket innsamlingsår teksten ble skrevet. 400-elevene har bare variabelen «4» og 700-elevene bare «7».
Denne bokstaven viser hvilken skrivehandling eleven fikk i oppdrag å skrive innenfor. Variablene er «b, f, o, r, s, u» og representerer den første bokstaven i skrivehandlingene:
Tallet forteller hvilken versjon en tekst har. Variablene er «0, 1, 2».
«0» betyr at teksten kun forekommer i én versjon.
«1» og «2» indikerer at eleven har skrevet flere versjoner av teksten. «1» betyr at dette er et utkast som skulle få tilbakemelding fra lærer (i noen tilfeller fins også skriftlig respons i tekstkorpuset). En ny versjon av teksten som ble skrevet etter tilbakemelding, har variabelen «2».
Denne bokstaven forteller hvilken type data teksten utgjør. Variablene i tekstkoden (fig. 2) er «i» for inngangstekster, «v» for tekster skrevet underveis i prosjektet (i korpusmenyen kalt skoletekster) og «u» for utgangstekster.
Inngangstekster er skrevet før intervensjonen startet på skolen. Elevene på alle fire trinn skrev to inngangstekster hver – alle som svar på de samme to oppgavene, én beskrivende oppgave («Beskriv snø for en …») og én forestillende oppgave («Tenk deg at …»). Fullstendig oppgaveformuleringer finnes i korpuset.
Skoletekstene er skrevet innenfor skolens ordinære undervisning og tilpasset lokale planer for ulike fag. Oppgavene er designet av lærerne. En føring fra prosjektet var at det skulle lages oppgaver som inviterte til skriving innenfor alle de seks skrivehandlingene i løpet av ett skoleår.
Utgangstekster er tekster skrevet etter at intervensjonen var avsluttet på skolen. Alle elevene skrev én utgangstekst, 400-og 700-elevene etter ett år og 300- og 600-elevene etter to år. Oppgavene var ulike på de ulike trinnene – og informasjon om oppgavene finnes i informasjonen til hver tekst.
Dette tallet angir rekkefølgen på oppgavene eleven har skrevet. Variablene er 1-7.
De to inngangsdatatekstene er merket med i_1 («snøtekster») og i_2 («spøkelsestekster»).
Tekster skrevet underveis i prosjektet (merket v) har oppgavenummer 1–6. Dette gjelder både for tekster fra første og andre innsamlingsår og må derfor sees i sammenheng med elevens trinn da teksten ble skrevet (se 3.1.6).
Merk at på e-skolen (Engen) har 300-elevene skrevet 7 tekster underveis i prosjektet (merket «v») andre innsamlingsår. Disse tekstene har fått oppgavenummer «7», til tross for 7-tallet ellers markerer at teksten er en utgangstekst. Tekstkoden vil da eksempelvis se slik ut: e303gn_4u0v_7.
Utgangsdatatekstene er merket u_7.
Tekstnummeret, i kombinasjon med info om datatype, viser i hvilken rekkefølge tekstene ble skrevet det aktuelle skoleåret. Ut fra disse opplysningene er det således mulig å følge elevens utvikling.
3.1.11 Hva kan vi lese ut av tekstkoden?
Tekstkoden gir altså informasjon både om elever og om tekstene de har skrevet. Eksempel-koden i309jn_4b0v_1forteller følgende:
Eleven ...
Teksten ...
Oppgaveformuleringene som elevene har fått, finner man ved å klikke på det blå informasjonstegnet som kommer opp til venstre på skjermbildet med søkeresultatene for hver tekst.
Alle tekstene er tagget automatisk med Oslo-Bergen-taggeren som utstyrer alle ord i teksten med lemma, ordklasse og annen morfologisk informasjon. Informasjonen er søkbar i korpuset, se punkt 4.1 og 4.2. Vær oppmerksom på at det kan være feil i taggingen siden denne er gjort automatisk!
De transkriberte tekstene er i tillegg tagget manuelt med formattagger og tagger for enkelte feil, for uforståelig tekst osv. Disse taggene er søkbare:
Les mer om dette i transkripsjonsrettledningen.
Navn har fått sine egne koder, se 3.4.
Personidentifiserende opplysninger i tekstene er anonymisert. Dette kan være opplysninger som:
Anonymiseringen er utført ved at det er satt hvit lapp over det eleven har skrevet i originalteksten. Som regel vil det på disse lappene stå hvilken type informasjon som er anonymisert: om det er personnavn, stedsnavn eller andre typer opplysninger. I de transkriberte tekstene er navnene erstattet med koder: &&M for guttenavn, &&F for jentenavn, &&S for stedsnavn og &&N for øvrige navn. Ulike navn gis ulike nummer, og disse deles ut fortløpende innafor hver kategori: &&F1, &&F2, &&F3 osv. Les mer om navn i transkripsjonsrettledningens punkt 3.3.2.
Normkorpuset bruker Tekstlaboratoriets søkegrensesnitt nye Glossa. Glossa er laget for søk i lingvistisk taggede korpus og gjør det mulig å søke i et rikt utvalg av tekster og språklige variabler. Ved hjelp av Glossa og en vanlig nettleser kan man gjennomføre søk basert på den informasjonen som finnes her. Man kan velge å søke i hele korpuset eller i deler av det.
Den følgende veiledningen viser hvordan du kan søke i Normkorpuset med Glossa.
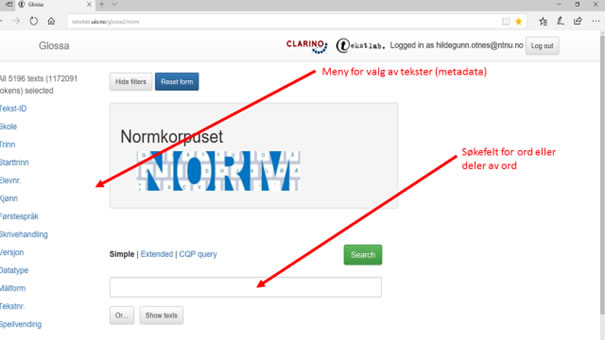
Etter innlogging via Feide eller tilsvarende, møter du søkesiden for Normkorpuset. Her kan du finne tekster og informasjon om disse, søke på ord, deler av ord og ordkombinasjoner, eller søke på spesifikke språktrekk basert på automatisk tagging.
Figur 4 viser hvordan søkegrensesnittet ser ut ved innlogging:
Figur 4: Søkesiden for Normkorpuset
I menyen for valg av tekster til venstre i skjermbildet (se figur 4 over) kan du avgrense tekstutvalget du søker i, basert på de opplistede kriteriene – skole, trinn, skrivehandlinger etc. Ved å klikke på de enkelte kriteriene, får du opp en meny som viser de ulike valgmulighetene:
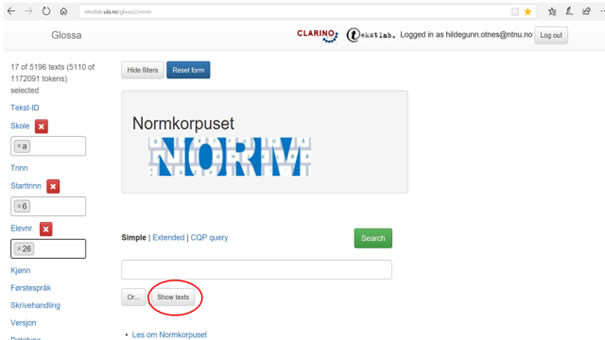
Figur 5a illustrerer hvordan du kan avgrense tekstutvalget. Det er her krysset av for skole a + starttrinn 6 + elev 26. Ved å klikke Show texts får du opp alle tekstene elev a626 har skrevet – både både i 6. og 7. klasse. (Hvis du hadde krysset av for trinn 7 i tillegg, ville du fått opp kun de tekstene den samme eleven har skrevet i 7. klasse).
Figur 5a: Eksempel på spesifisert tekstsøk
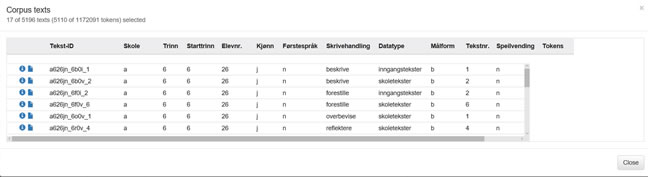
Figur 5b: Resultatet av søket i figur 5a
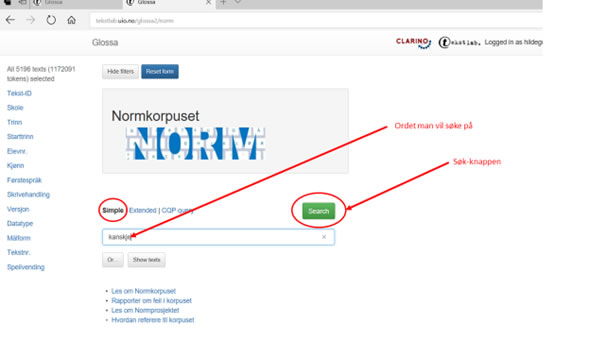
Gjennom såkalt "enkelt søk' kan du søke på enkeltord eller flere ord sammen i tekstene, slik figur 6a illustrerer:
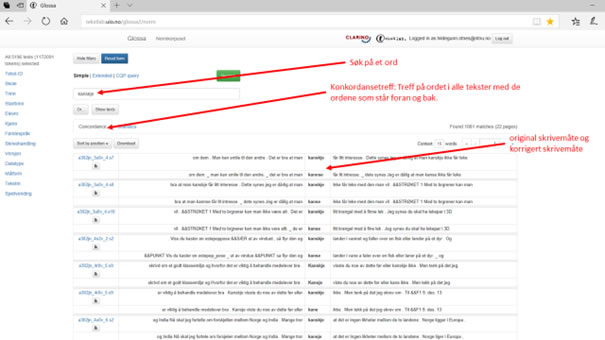
Figur 6a: Enkelt søk på ordet 'kanskje'
Figur 6b viser resultatene av dette søket i hele materialet. (Her har vi altså ikke valgt tekster fra spesifikke kategorier.)
Figur 6b: Konkordansetreff – enkelt søk på ordet 'kanskje'
Søkeresultatene presenteres her som en konkordans med normert versjon først og elevens originale skrivemåte under – der ordene vises i kontekst. Antall treff står over søkeresultatene til høyre. I det lille vinduet (merket «Context») som står til venstre under antall treff, kan du spesifisere hvor omfattende kontekst du vil ha med (15 ord er forhåndsvalgt). Det presenteres 50 søkeresultater per side. Er det flere, kan du klikke deg videre ved hjelp av pilene til høyre.
Til venstre for søkeresultatene er det et tekstsymbol. Klikker du på dette, får du opp selve teksten i pdf-format. Over tekstsymbolet står elevkoden til eleven som har skrevet teksten. Klikker du på den, får du mer informasjon om eleven.
Hvis du klikker på «Show texts», får du også opp informasjon om tekstene treffene er hentet fra og metadata om eleven. Her får du også opp en info-knapp som rommer informasjon om oppgaveteksten og annen relevant kontekstinformasjon.
Figur 7: Informasjonsknapp og tekstsymbol
Ved å holde muspekeren over ord i et konkordansetreff, får du opp et lite vindu med informasjon om lemma, ordklasse, annen morfologisk informasjon og tagger. (Les mer om søk på ordklasser og ulike tagger 4.2.5 og 4.2.6 under.)
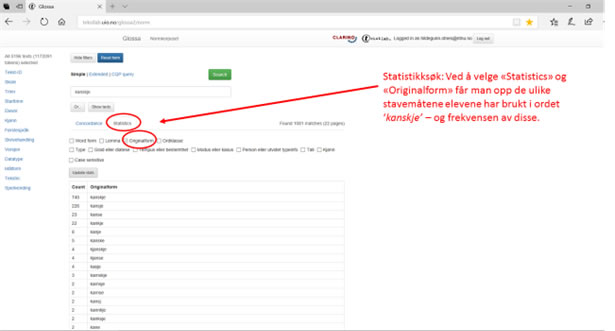
Du kan også få ulike statistiske visninger av søkeresultatet ved å velge 'Statistics' – se eksempel og forklaring i figur 8. Husk å klikke «Reset form» og eventuelt «Update stats» mellom hvert søk.
Figur 8: Statistikk
Over søkeresultatene er det også knapper for nedlasting og sortering – «Download » og «Sort by position». Disse kan danne utgangspunkt for videre bearbeiding av materialet.
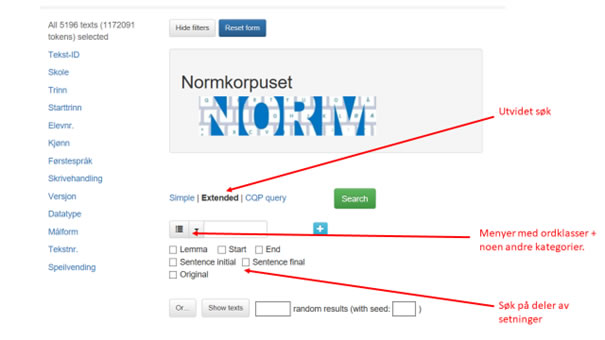
Hvis du klikker «Extended» i søkeskjemaet, får du flere søkemuligheter og kan søke både på enkeltord og fraser, på lemma, starten eller slutten på ord eller på begynnelsen eller slutten av en setning. Du kan også søke på ordklasser, morfologiske trekk eller andre tagger i materialet.
Her kan du velge om søkeordet skal være et helt ord, lemma, begynnelsen av et ord, slutten av ord m.m.
Eksempel: Søkeordet 'bok' i kombinasjon med spesifikasjonen «lemma» fra menyen gir alle bøyningsformer av 'bok' som søkeresultat: 'bok, 'boken', 'boka', 'bøker' og 'bøkene'. Spesifiserer du søkeordet 'bok' med «Start», får du også søkeresultater som 'boksen', 'bokstaver' og 'bokanbefaling'.
Du kan også søke etter flere ord samtidig.Hvis du klikker på det blå plusstegnet til høyre, får du opp en søkeboks til. Du kan lage så mange søkebokser du vil. Mellom søkeboksene kan du definere hvor mange ord det minimum eller maksimum skal være mellom søkeordene. Du fjerner en søkeboks ved å klikke på minustegnet til høyre i boksen.
Du kan også velge å søke etter ordklasse eller annen lingvistisk informasjon i søkeboksene, se også 4.2.5.
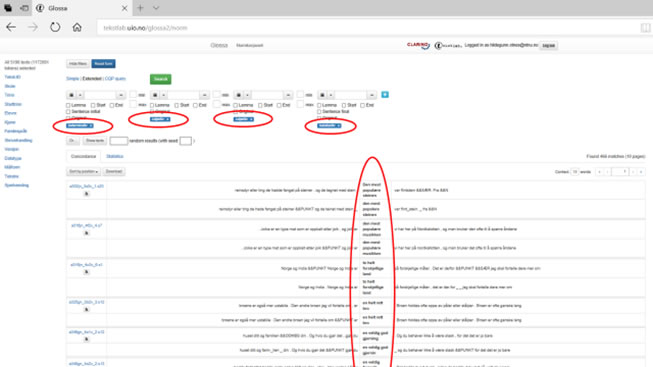
Figur 10: Søk på fraser bestående av determinativ + adjektiv + adjektiv + substantiv
4.2.3 Søk på 'Lemma', 'Start', 'End', 'Original', 'Sentence initial' eller 'Sentence final'
Under søkevinduet er det seks bokser der du kan krysse av for «Lemma», «Start», «End», «Original», «Sentence initial» eller «Sentence final». Se om lemma-søk under 4.2.1. Dersom du krysser av for «Start» eller «End», får du alle ordene som enten begynner eller starter med ordet eller bokstavene som står i søkeboksen. Et søk på arbeid der «Start» er krysset av, kan gi resultater som 'arbeidsmuligheter' eller 'arbeidsledighet'. Er «End» krysset av, kan resultatene være ord som 'fredsarbeid', 'samarbeid' eller 'husarbeid'.
Krysser du av for «Sentence initial», søker du bare på ord på førsteplass i setningene. Et kryss i Sentence final betyr søk på det siste ordet. Figur 11 viser et søk på ordet 'jeg' i «Sentence initial».
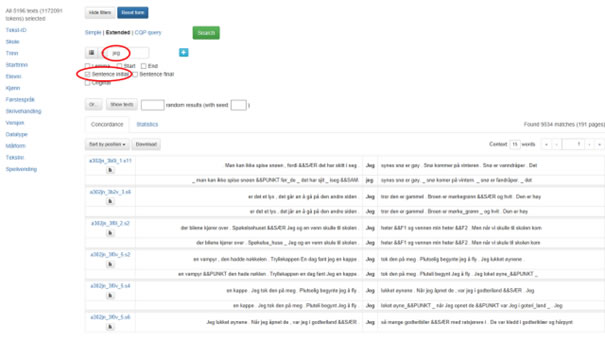
Figur 11: Søk på 'jeg' i begynnelsen av setninger.
Elevtekstene i Normkorpuset finnes i to versjoner som kommer opp i søkeresultatene: normert versjon og elevens originalversjon. Vanligvis søker du i de normerte versjonene av tekstene.
Vil du heller søke i originaltekstene, krysser du av for «Original» i menyen. Søker du f.eks. på den unormerte formen 'kansje' og krysser av for «Original», får du 20 treff som viser at elever har brukt denne varianten. Slik kan du f. eks. søke etter spesifikke skrivefeil. Du kan også søke i original og normert versjon samtidig, se 4.2.7.
Eksempel: Et vanlig søk på 'vær' gir treff på imperativ av 'være' og ubestemt form entall av substantivet 'vær'. Et søk på 'vær' spesifisert som 'original' gir også treff der 'vær' er feilstavet for 'hver'.
4.2.5 Ordklasse ('Part of speech') og/eller morfologiske trekk
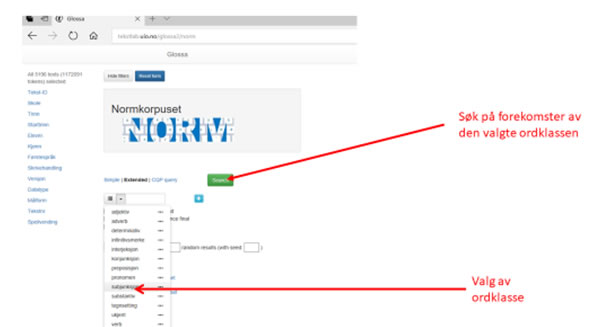
Ved å klikke menyfeltet merket i figur 12, kan du velge ordklasse og andre spesifikke trekk for søkeordet ditt (se også 4.2.2 om søk på flere ordklasser). Merk at menyen fins i to formater, der listeformatet (til venstre) er mer spesifikt enn nedtrekksmenyen bak pilen.
Figur 12: Søk på ordklasse – subjunksjon
Du kan også velge å søke f. eks. etter alle adjektiv i hele eller en deler av korpuset ved å velge ordklasse uten å skrive inn enkeltord. Her kan du spesifisere søket ved å for eksempel legge til flere morfologiske trekk, som flertall eller nøytrum.
Hvis du klikker på flere ordklasser samtidig, for eksempel både substantiv og pronomen, vil du få treff på alle ordene som er enten substantiv eller pronomen. Tilsvarende kan du klikke på flere variabler innenfor en kategori, for eksempel både hunkjønn og hankjønn i kategorien kjønn under substantiv for å få treff på substantiv som er enten hunkjønn, hankjønn eller begge deler.
4.2.6 Søk på andre tagger (særskriving mfl.)
I transkripsjonen er samskrivings- og særskrivingsfeil rettet, dels av hensyn til koblingen mellom original og normert versjon. Det er satt inn tagger i originalversjonen der en feilaktig samskriving er delt opp i den korrigerte versjonen. I den korrigerte versjonen er det satt inn tagger der særskriving er rettet. Disse taggene er det mulig å søke på direkte i materialet.
Eksempler:
I den normerte teksten er det også satt inn tagger for noen av fenomenene som ikke lar seg representere i en tekstfil, for eksempel tegninger (&&TEGNING), eller der deler av teksten er strøket over (&&STRØKET). Vær oppmerksom på at også små symboler, som eksempelvis smilefjes i teksten, er tagget som tegning.
Du finner søkemulighetene for taggene i samme boks som ordklassene og søk på detaljert morfologisk informasjon, klikk på listeformatet til venstre for ordsøkeboksen. Se også figur 13.
4.2.7 Spesifiser eller ekskluder lemma og ordform
Nederst i søkeboksen «Parts of speech» er det et felt der du ytterligere kan spesifisere et søk. Velger du for eksempel verb i den morfologiske søkeboksen, men bare er ute etter hjelpeverbene, kan du velge «Specify lemma» og legge til hjelpeverbene ett for ett i boksen til høyre og trykke OK mellom hver gang.
Dersom du har valgt verb, men ikke vil ha med hjelpeverbene, gjør du det på samme måte, men velger «Exclude word form» eller «Exclude lemma».
Har du valgt å søke etter «Original» (se 4.2.4 over), kan du spesifisere hvilken korrigert ordform eller lemma ordet skal ha i «Specify word form» eller «Specify lemma». Søk for eksempel på 'å' og kryss av for original i den vanlige søkeruten. Så velger du «Specify word form» 'og', og du får alle tilfeller av denne typen og/å-feil. Et annet eksempel er å søke på 'får' og krysse av for original og deretter «Specify word form» 'for' og du får opp alle forekomstene der eleven har forvekslet disse to formene. Slike søk er særlig relevante der ord kan forveksles.
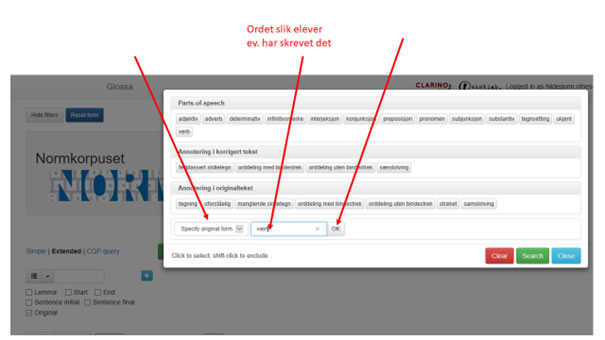
Figur 13 viser et søk på 'vært' versus 'hvert'. Her er den riktige formen skrevet inn i hovedsøkeboksen mens «Specify original form» 'vært' er skrevet inn i boksen for spesifikasjoner.
NB! Husk å klikke på OK når du har skrevet inn et ord i boksen.
Figur 13: Spesifisert søk på ord som kan forveksles
Merk at søkene som er demonstrert hittil, har tatt utgangspunkt i hele materialet. Alle søkene kan imidlertid også gjennomføres i avgrensede utvalg, som f. eks. utvalgte skoler eller trinn, blant enkeltelever eller innenfor spesifikke skrivehandlinger. Velg hvordan du vil begrense søket i menyen til venstre, se figur 4 og figur 5a for eksempel.
4.3.1.CQP-søkeuttrykk (CQP query)
CQP-søkeuttrykk kan brukes til avanserte søk som ikke er mulige i enkelt eller utvidet søk. For å bruke denne muligheten må du kunne CQP-søkespråket. Om du trenger hjelp til et avansert søk, kan du ta kontakt med Tekstlaboratoriet. Dersom du har brukt mulighetene i «Extended search» og lurer på hvordan dette søket ser ut på CQP-søkespråket, klikker du på «CQP query», så får du opp søkeuttrykket.
Tips: Dersom du er ute etter å finne alle ord som har ulik original og korrigert form, det vil si alle korrigerte skrivefeil i korpuset, skriver du:
a:[] :: a.word != a.orig
i CQP query-boksen uten []-klammene rundt.
Ved å klikke på Or-boksen får du opp et nytt søkevindu under det andre. Søk i denne boksen gir et eller-søk. Det vil si at du søker på ordet i hovedsøkeboksen eller ordet i Or-boksen. Du kan lage så mange Or-bokser du vil, og du sletter dem ved å klikke på det røde krysset til venstre for boksen.
Figur 14a og b viser et komplisert søk etter verb i preteritum som ender på enten -et eller -a. Verbene 'het', 'bet', 'slet, 'sa', 'la' og 'ga' er ekskludert.
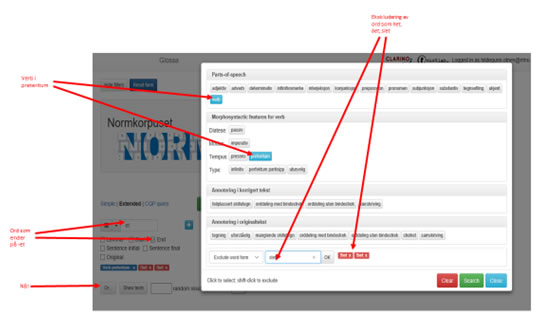 Figur
Figur
14a: Komplisert søk, verb i preteritum: -et eller -a
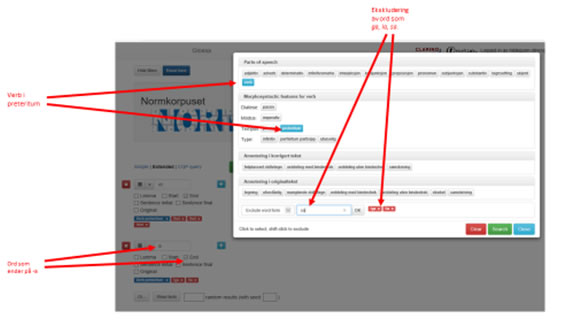
Figur 14b: Komplisert søk, verb i preteritum: -et eller -a
Klikker du på «Download»-knappen over søkeresultatene, får du opp en dialogboks der du kan velge flere nedlastingsformater: Excel-fil, tab-separert tekstfil eller kommaseparert tekstfil. Du kan også velge hvilken informasjon som skal lastes ned.
Søkeresultatene kan sorteres på ulike måter: Dersom du vil sortere etter søkeordet, velger du «Sort by match». Du kan også sortere etter ordet umiddelbart til venstre eller ordet umiddelbart til høyre. Legg merke til at skilletegn blir alfabetisert før a og b osv.