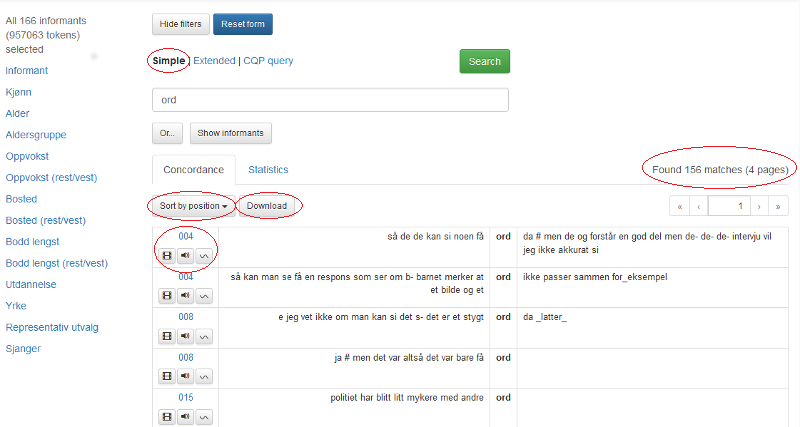
Figur 1 viser hovedsøkesiden til NoTa-Oslo:
Figur 1: Hovedsøkesiden NoTa-Oslo.
Brukerveiledning for Norsk talespråkskorpus - Oslodelen
(NoTa-Oslo)
Norsk talespråkskorpus - Oslodelen (NoTa-Oslo) har fått nytt søkegrensesnitt: https://tekstlab.uio.no/glossa3/nota_oslo
Denne nye versjonen av søkegrensesnittet
Glossa er i hovedsak lik den gamle, men har noen nye funksjoner.
Se hvordan du kan bruke den nye versjonen av Glossa i to instruksjonsvideoer:
Denne brukerveiledningen er skrevet for den gamle versjonen av søkegrensesnittet: https://tekstlab.uio.no/glossa2/nota_oslo
Kontakt tekstlab-post@iln.uio.no om du har spørsmål.
Brukerveiledningen er skrevet av Kristin Hagen og bygger på The Nordic Dialect Corpus - Search Interface Documentation skrevet av Eirik Olsen.
1. NoTa-Oslo
NoTa-Oslo består av intervjuer og samtaler med 166 informanter født og oppvokst i Oslo og Oslo-området. Informantene er representative med hensyn til alder, kjønn, bosted og utdannelse. Opptakene er gjort i perioden 2004 - 2006.
På denne siden:
1.1 Transkripsjonene i NoTa-Oslo
1.2 Hovedsøkesiden til NoTa-Oslo
1.2.1 Enkelt søk (simple) og eksempel på resultatvisninger
1.2.2 Utvidet søk (Extended)
1.2.2.1 Søk på flere ord
1.2.2.2 Søk på Lemma, Start, End, Segment initial eller Segment final
1.2.2.3 Søk på ordklasse eller morfologiske trekk
1.2.2.4 Søk på andre tagger (latter, ord som ikke står i ordboka osv)
1.2.2.5 Spesifiser eller ekskluder lemma og ordform
1.2.3 CQP-søkeuttrykk (CQP query)
1.2.3.1 Søk på uttalevarianter av pronomen i CQP query
1.2.4 Eller-søk (Or)
1.3 Metadatasøk og Show informants
1.4 Tilfeldig utvalg av søkeresultatene
1.5 Statistikk
1.6 Last ned data
1.1 Transkripsjonene i NoTa-Oslo
Opptakene er transkribert ved hjelp av transkripsjonsprogrammet Transcriber. Her blir transkripsjonene koplet sammen med lyd- og bildefilene.
Opptakene er transkribert ortografisk, men ord for ord uten å endre ordstillingen. Du kan lese transkripsjonsveiledningen for NoTa-Oslo her. Transkripsjonene er tagget med NoTa-taggeren, en statistisk talemålstagger (TreeTagger) som er trent på talemålsmaterialet fra NoTa-Oslo. Her kan du lese taggeveiledningen.
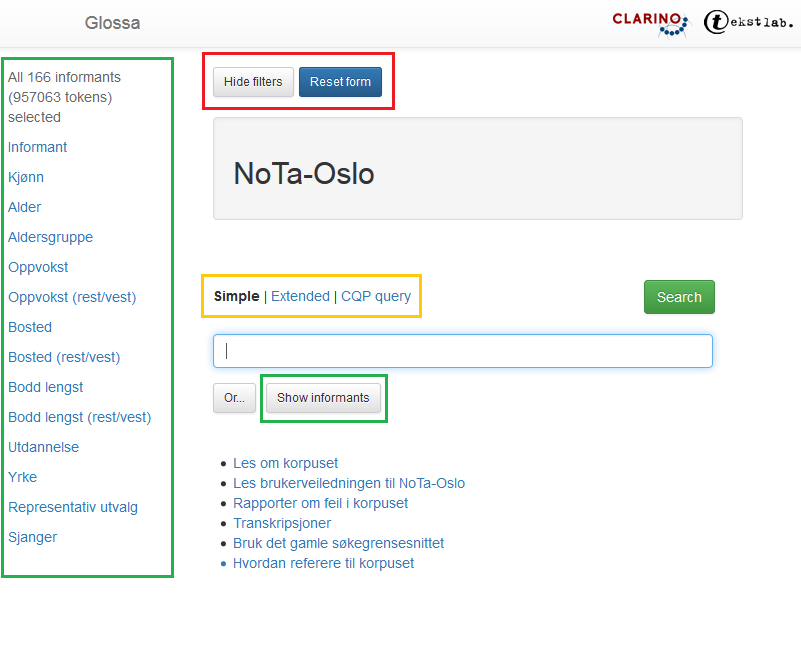
1.2 Hovedsøkesiden til NoTa-Oslo
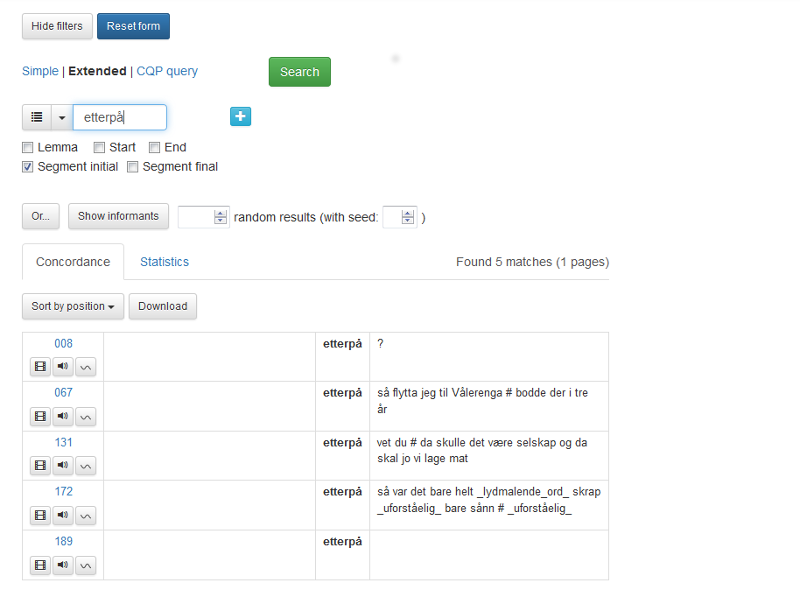
Figur 1 viser hovedsøkesiden til NoTa-Oslo:
Figur 1: Hovedsøkesiden NoTa-Oslo.
Til venstre er alle metadatakategoriene det går an å søke i. I NoTa-Oslo er dette forskjellige egenskaper hos informantene: Informant, Kjønn, Alder, Aldersgruppe, osv. Du ser hvor mange informanter som er valgt over metadatakategoriene.
Knappen Show informants gir deg en oversikt over alle informantene eller det utvalget informanter du har valgt. Les mer under 1.3.
Øverst er to knapper. Med Hide filters kan du skjule metadatakategoriene til venstre.
Reset form gir deg en blank søkeside.
Resten av søkesiden handler om søkeordet eller egenskaper ved det. Les mer nedenfor.
1.2.1 Enkelt søk (simple) og eksempel på resultatvisninger
I enkelt søk (Simple) kan du søke på enkeltord og fraser i søkefeltet. Resultatene vises som en konkordans (se figur 2). Du kan se antall treff over søkeresultatene til høyre. Det presenteres 50 søkeresultater per side. Er det flere, presenteres de over flere sider som man kan klikke seg inn på.
Over søkeresultatene finner du knapper for nedlasting og sortering, se 1.6. og 1.7. Du kan også få ulike statistiske visninger av søkeresultatet, se 1.5.
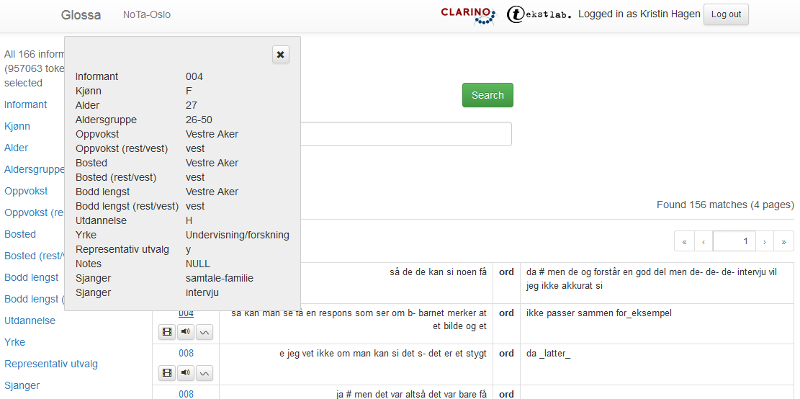
Dersom du holder musa over ordet, får du opp et lite vindu med informasjon om lemma, ordklasse, annen morfologisk informasjon og tagger, se figur 2a. Les mer om ordklasser og tagger i 1.2.2.3 og 1.2.2.4.
Til venstre for søkeresultatene er det tre ikoner. Klikk på videoikonet for å se video av søkeresultatet (se figur 3). Klikk på lydikonet for å kun få opp lyd (se figur 4). I avspillingsboksen for lyd og bilde kan man få mer kontekst ved å dra firkantene under boksen til venstre og/eller høyre.
Klikk på det siste ikonet for å få opp lydbølge og spektrogram for søkeresultatet (se figur 5). Klikk på informantnummeret for å få opp metadata om informanten (se figur 6).
Figur 2: Søkeresultat for enkeltord i talekorpuset.
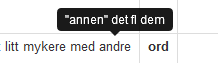
Figur 2a: Dersom du holder musa over et ord i søkeresultatet, får du opp et lite vindu med informasjon om ordklasse, annen morfologisk informasjon og tagger.
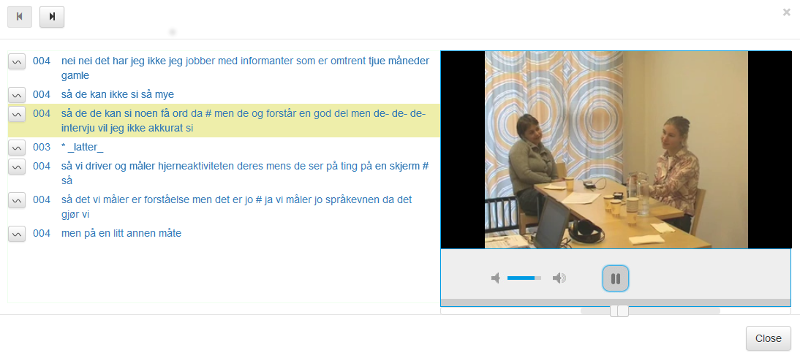
Figur 3: Videovisning av søkeresultatet. Dra i firkantene under avspillingsboksen for å få mer kontekst.
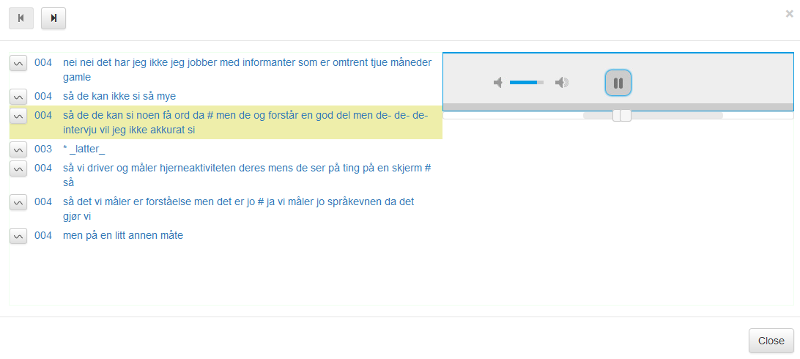
Figur 4: Lydavspilling av søkeresultatet.
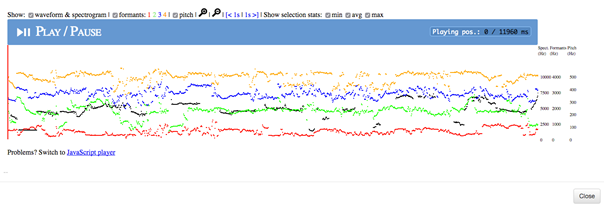
Figur 5: Lydbølge og spektrogram.
Figur 6: Metadata om informanten.
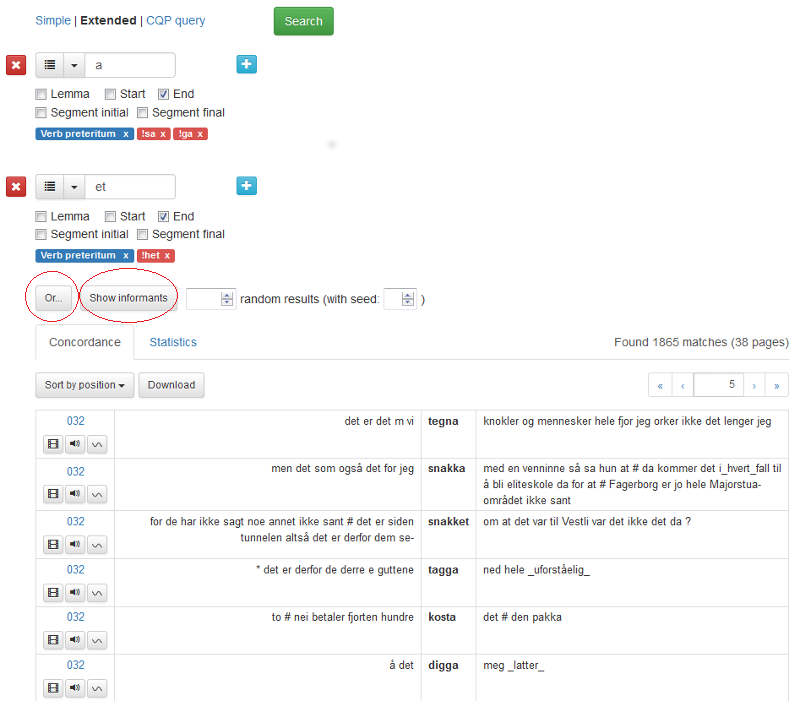
1.2.2 Utvidet søk (Extended)
Utvidet søk (se figur 7) gir flere søkemuligheter. Du kan søke både på både enkeltord og fraser, på lemma, starten eller slutten på ord eller på begynnelsen eller slutten på segment. Du kan også søke på ordklasser, morfologiske trekk eller andre tagger.
1.2.2.1 Søk på flere ord
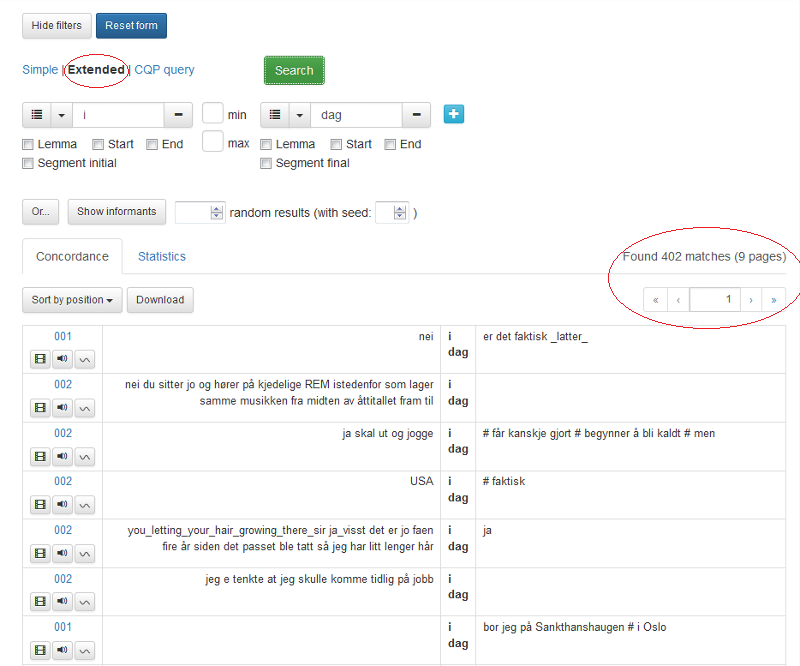
Dersom du fyller inn noe i den første søkeboksen og klikker på det blå plusstegnet til høyre, får du opp en søkeboks til. Du kan lage så mange søkebokser du vil. Mellom søkeboksene kan du definere hvor mange ord det minimum eller maksimum skal være mellom søkeordene. Du fjerner en søkeboks ved å klikke på minustegnet til høyre i boksen.
I figur 8 er det gjort et søk på frasen i dag. Det er funnet 402 resultater som presenteres over 9 sider. Klikk på pilene for å navigere i søkeresultatene.
NB! Vær oppmerksom på at noen fraser er skrevet som enkeltord på denne måten: for_eksempel. Dette er fordi korpuset er preprosessert med Oslo-Bergen-taggeren som har endel flerordsuttrtykk som enkeltlemma. Se en oversikt over uttrykkene her.
Figur 8: Søk på flere ord.
1.2.2.2 Søk på Lemma, Start, End, Segment initial eller Segment final
Under søkevinduet er det fem bokser der man kan krysse av for Lemma, Start, End, Segment initial eller Segment final. Dersom du krysser av for Lemma, får du alle bøyingsformer av et ord som resultat, for søkeordet bok får du både bok, boka, boken, bøker og bøkene som resultat dersom ordene finnes i korpuset.
Krysser du av for Start eller End, får du alle ordene som enten begynner eller starter med ordet eller bokstavene som står i søkeboksen. Et søk på bok der Start er krysset av, kan gi resultater som bokorm eller bokomslag. Er End krysset av, kan resultatene være ord som grammatikkbok eller notisbok.
Transkripsjonene i NoTa-Oslo består av segmenter og ikke setninger i skriftspråklig forstand. Segmentene er skilt fra hverandre, ikke med punktum, men med tidskoder som angir hvor i videoen eller lydfila segmentet starter eller stopper. Segmentene vil ofte tilsvare skrifspråklige setninger, men siden dette er talemål, kan det også være snakk om ufullstendige setninger uten subjekt og finitte verbal.
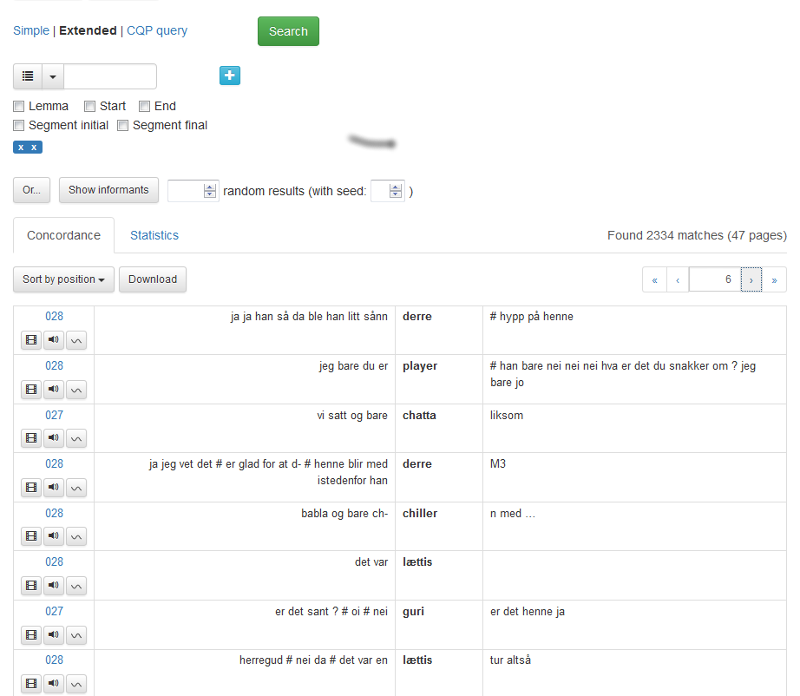
Krysser du av for Segment initial, spesifiserer du at søkeuttrykket skal komme først i et segment. Et kryss i Segment final betyr søk på det siste ordet. Figur 9 viser et søk på ordet etterpå i Segment initial.
Figur 9: Etterpå i Segment initial-posisjon.
1.2.2.3 Søk på ordklasse eller morfologiske trekk
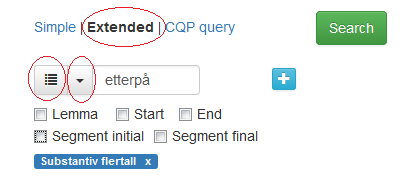
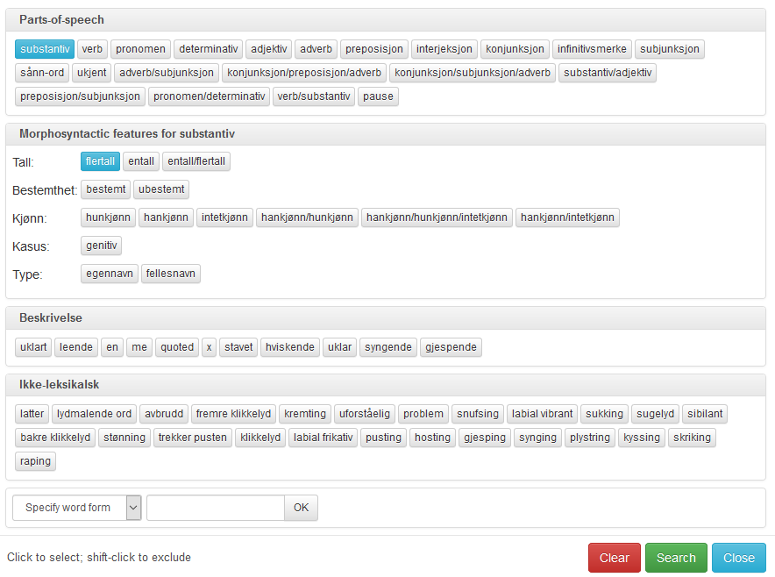
I utvidet søk kan du søke på ordklasse ved å bruke nedtrekksmenyen som skjuler seg bak pilen til venstre i søkeboksen, se figur 10. Klikker du på knappen til venstre for pilen, får du opp boksen i figur 11. Velger du en ordklasse under Parts-of-speech, får du også tilgang til valgene under Morphosyntactic features for den ordklassen du har valgt. Valgene dine kommer opp i små blå bokser under søkefeltet. I figur 10 er det søkt på Substantiv flertall.
De andre avkryssingsmulighetene i boksen på figur 11 blir forklart i kapitlene under.
Figur 10: Knappene for ordklassesøk og søk etter andre morfologiske trekk.
Figur 11: Søk på ordklasse og annen morfologisk informasjon.
Hvis du klikker på flere ordklasser samtidig, for eksempel både substantiv og pronomen, vil du få treff på alle ordene som er enten substantiv eller pronomen.Tilsvarende kan du klikke på flere verdier innafor en kategori, for eksempel både hunkjønn og hankjønn i kjønn-kategorien under substantiv for å få treff på substantiv som er enten hunnkjønn, hannkjønn eller begge deler.
NoTa-Oslo er automatisk tagget med NoTa-taggeren. Du kan lese om valgene som er tatt for taggingen i taggeveiledningen.
1.2.2.4 Søk på andre tagger (latter, ord som ikke står i ordboka osv.)
Under beskrivelse og ikke-leksikalsk i søkeboksen beskrevet under 1.2.2.3 ovenfor (figur 11) kan du søke på tagger som enten beskriver ordene eller som er selvstendige hendelser i talestrømmen:
Beskrivelse:
Uklart: Ord som transkribøren er usikker på
Leende: Ord som blir sagt leende
En: engelsk(e) ord
Me: står for meningsenhet og brukes ved overlappende tale der taler 2 tar over turen. Les mer om dette fenomenet i transkripsjonsveiledningens kapittel 3.6.
Quoted: ord i hermetegn, det vil si sitater og navn på filmer, bøker og leker osv som består av flere ord.
X: Opptakene er transkribert ortografisk med Bokmålsordboka (2005) som rettesnor. Ord som ikke står i ordboka, er merket med taggen x. I NoTa-Oslo er dette som regel slangord eller ord fra andre språk. Engelske ord har sin egen tagg i NoTa-Oslo, men noen ord med engelsk opphav har nok likevel fått x-tagg.
Stavet: Ord som blir uttalt bokstav for bokstav.
Hviskende/syngende/gjespende: ord som blir hvisket, sunget eller blir sagt mens informanten gjesper.
Krysser du av for én eller flere av taggene ovenfor, får du ordene som er knyttet til dem som resultat.
Ikke-leksikalsk:
I denne kategorien finner vi latter, lydmalende ord, klikkelyder, kremting, snufsing osv. Dette er altså selvstendige hendelser i talestrømmen.
Uforståelig: ett eller flere ord som er så utydelige at transkribøren ikke en gang klarer å gjette hva som blir sagt.
Problem: Transkribøren har signalisert at hun/han har oppdaget et problem de ikke klarer å løse.
Krysser du av for én eller flere av taggene ovenfor, får hendelsen selv - for eksempel latter - som resultat.
I figur 12 er det søkt etter ord som ikke er i ordboka. player og chiller er blant resultatene.
Figur 12: Søk på ord som ikke står i ordboka.
1.2.2.5 Spesifiser eller ekskluder lemma og ordform
Nederst i
den morfologiske søkeboksen i figur 11 er det et felt der du ytterligere kan spesifisere et søk. Velger du for eksempel verb i den morfologiske søkeboksen, men bare er ute etter hjelpeverbene, kan du velge Specify lemma og legge til hjelpeverbene ett for ett i boksen til høyre og trykke OK mellom hver gang.
Dersom du har valgt verb, men ikke vil ha med hjelpeverbene, gjør du det på samme måte, men velger Exclude word form eller lemma.
NB! Husk å klikke på OK når du har skrevet inn et ord i boksen! Ord som er ekskludert, vil da komme opp på høyre side i rødt med et utropstegn foran, se figur 13 og figur 15. Ord som er spesifisert, kommer opp i blått.
Figur 13: Spesifiser eller ekskluder lemma og ordform.
1.2.3 CQP-søkeuttrykk (CQP query)
CQP-søkeuttrykk kan brukes til avanserte søk som ikke er mulige i enkelt eller utvidet søk. For å bruke denne muligheten må du kunne CQP-søkespråket. Om du trenger hjelp til et avansert søk, kan du ta kontakt med Tekstlaboratoriet. Figur 14 viser et eksempel på hvordan søk etter ordene i dag etterfulgt av substantiv eller pronomen ser ut i enten utvidet søk (Extended) eller i CQP query. Dersom du har brukt mulighetene i Extended search og lurer på hvordan dette søket ser ut på CQP-søkespråket, klikker du på CQP query, så får du opp søkeuttrykket som i figur 14.
Figur 14: Eksempel på samme søk i Extended og CQP query
1.2.3.1 Søk på uttalevarianter av pronomen i CQP query
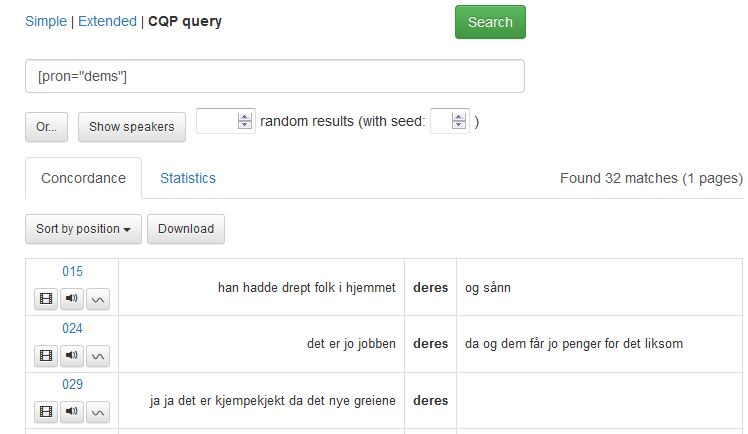
I Nota-Oslo er personlige pronomen behandlet spesielt. De er transkribert som vanlig med Bokmålsordboka som norm, men dersom uttalen avviker fra uttalen i standard østnorsk, er også uttalen transkribert. Dette vil du ikke se i resultatvisningen, men det er mulig å søke etter disse uttalevariantene ved hjelp av et cqp-søk, se figur 14b.
Figur 14b: Eksempel på søk etter pronomenet deres uttalt som dems. Legg merke til at resultatvisningen bare viser standardformen
Det er altså bare uttale som avviker fra uttalen i standard østnorsk som markeres på denne måten. For eksempel markeres ikke at jeg uttales jei eller at meg uttales mei. Derimot spesifiseres for eksempel uttalen hu for hun og dom for dem.
1.2.4 Eller-søk (Or)
Ved å klikke på Or-boksen får du opp et nytt søkevindu under det andre. Søk i denne boksen gir et eller-søk. Det vil si at du søker på ordet i hovedsøkeboksen eller ordet i Or-boksen. Du kan lage så mange Or-bokser du vil, og du sletter dem ved å klikke på det røde krysset til venstre for boksen.
Figur 15 viser et komplisert søk etter verb i preteritum som ender på enten -a eller -et. Verbene sa, ga og het er ekskludert.
Figur 15: Or-søk.
1.3 Metadatasøk og Show informants
Til venstre i søkeskjemaet er alle metadatakategoriene ramset opp. For NoTa-Oslo er kategoriene Informant, Kjønn, Alder, Aldersgruppe, Oppvokst, Oppvokst (rest/vest), Bosted, Bosted (rest/vest), Bodd lengst, Bodd lengst (rest/vest), Utdannelse, Yrke, Representativt utvalg og Sjanger.
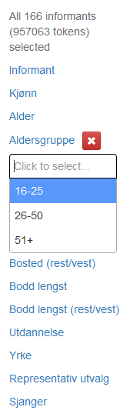
Klikker du på en av lenkene, kommer de ulike verdiene i hver kategori opp. Du kan klikke på og velge én eller flere, og valget du gjør, blir synlig i en boks under kategorien. Klikker du på det røde krysset, blir valget nullstilt. Figur 16 viser hvordan metadatamenyen ser ut når man har klikket på kategorien Aldersgruppe.
Figur 16: Metadatamenyen der det er klikket på Aldersgruppe.
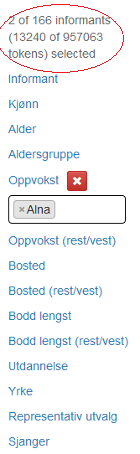
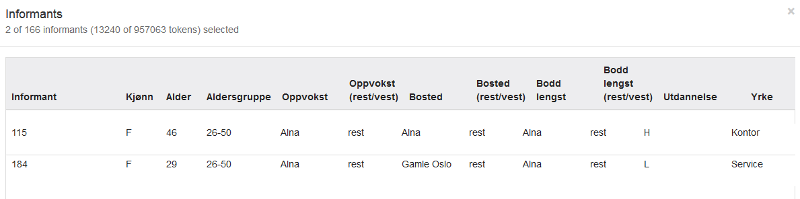
Valget du gjør, begrenser de videre mulighetene du har for søk. Har du valgt for eksempel M i kategorien Kjønn, vil du bare kunne velge verdier som er knyttet til de mannlige informantene. For eksempel vil du ikke få valget Alna under Oppvokst fordi det bare er kvinnelige informanter oppvokst i Alna i korpuset. I figur 17 er det krysset av for Alna under Oppvokst.
Figur 17: Alna er valgt under Oppvokst.
Over metadatakategorimenyen er det en teller som til enhver tid viser deg hvor mange informanter du har valgt og hvor mange tokens utvalget da består av. I denne versjonen inneholder NoTa-Oslo 166 informanter og 957 063 tokens (ord og skilletegn) slik figurene ovenfor viser. Når det er valgt bare informanter som er oppvokst i Alna, begrenser utvalget seg til 2 informanter og 13 240 tokens slik figur 17 viser.
Dersom du ønsker å se en samlet oversikt over informantene du har valgt, klikker du på Show informants-knappen nedenfor ordsøkeboksen ved siden av Or-knappen, se figur 15. Resultatet blir som i figur 18 for utvalget fra figur 17.
Figur 18: Show informants-vinduet.
De ulike metadatakategoriene er kort beskrevet nedenfor:
Informant: hver informant har fått tildelt et nummer i stedet for sitt virkelige navn. Du kan søke på én eller flere informantnummer.
Kjønn og alder: informantenes kjønn og alder.
Aldersgruppe: informantene er delt inn i tre aldersgrupper: 16-25, 26-50 og 51+.
Oppvokst: bydelen eller kommunen informanten er vokst opp i.
Oppvokst (rest/vest): oppvekstkommunene er kategorisert som Oslo vest eller Oslo rest. Oslo vest omfatter i tillegg til de tradisjonelle vestlige bydelene i Oslo, også Nordstrand, Asker og Bærum. Oslo rest er definert som de østlige bydelene i Oslo pluss andre omliggende kommuner i pendleravstand til hovedstaden.
Bosted: bydelen eller kommunen der informanten bodde da opptakene ble gjort.
Bosted (rest/vest): informantens bosted er kategorisert som rest eller vest.
Bodd lengst: bydelen eller kommunen der informanten har bodd lengst.
Bodd lengst (rest/vest): også bodd lengst-kategorien er klassifisert som rest eller vest.
Utdannelse: informantenes utdannelse er registrert som enten L (utdanning til og med videregående skole) eller H (utdanning utover videregående skole).
Yrke: Informantenes yrker ble delt inn i seks kategorier.
Representativt utvalg: 144 av informantene er med i det representative utvalget hvor det er like mange kvinner som menn, like mange i hver av de tre aldersgruppene, like mange høyt utdannede som lavt utdannede og like mange som har bodd lengst i Oslo rest som i Oslo vest.
Sjanger: informantene deltar i ett intervju og en samtale. Samtalene er i tillegg delt inn etter hvor godt informanten kjenner samtalepartneren.
Les mer om informantene på hjemmesiden til Nota-Oslo.
1.4 Tilfeldig utvalg av søkeresultatene
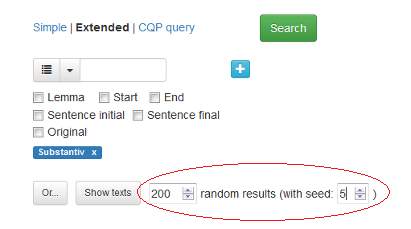
Dersom man har ett søk som vil gi mange treff, kan man velge å få se bare ett visst antall tilfeldig utvalgte treff. Spesifiser antall treff i boksen ved siden av Show texts.
Dersom du vil gjenskape akkurat dette resultatet senere, velger du et tall og setter det inn i boksen with seed. I figur 19 er er det søkt etter alle substantiv i korpuset, med en visning på 200 tilfeldig utvalgte treff. Tallet 5 er skrevet i with seed-boksen. Hver gang du gjør det samme søket og skriver det samme tallet i boksen, får du det samme tilfeldige utvalget av søkeresultatene. Skriver du et annet tall, får du et annet tilfeldig utvalg.
Det er mulig å velge tilfeldig utvalg av søkeresultatene for søk som er Extended eller CQP query.
Figur 19: Avkrysningsboks for å få et tilfeldig utvalg av søkeresultatene, her med 200 tilfeldige resultater.
1.5 Statistikk
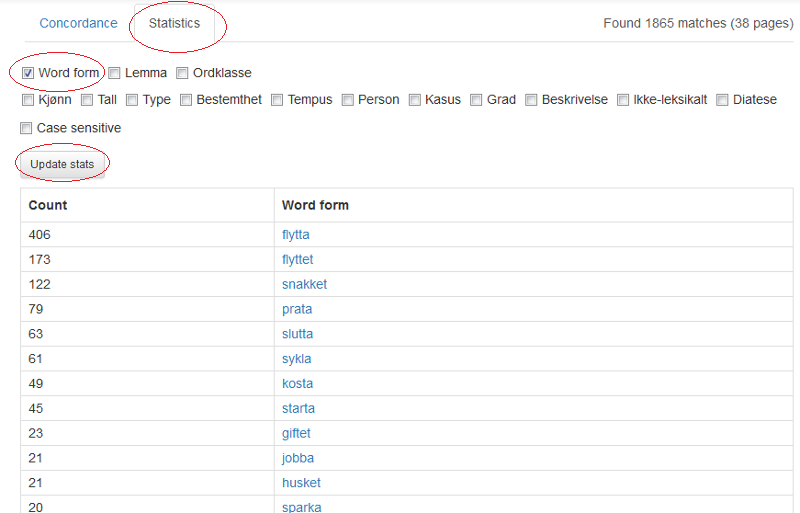
Søkeresultatvisningen Concordance er den som er forhåndsvalgt og som alle eksemplene ovenfor er hentet fra. Velger du Statistics som i figur 20 nedenfor, kan du be om ulike frekvenstellinger og statistikk. Foreløpig er det boksene over Update stats som kan velges. Klikk av for hva du vil se, og trykk Update stats. Eksempel 20 viser frekvenser fra søket i figur 15, altså søk etter verb i preteritum som ender på enten -a eller -et. Verbene sa, ga og het er ekskludert. Frekvensene er til venstre og ordformen til høyre.
Figur 20: Statistikkvisning for søkeresultatet fra figur 15.
1.6 Last ned data
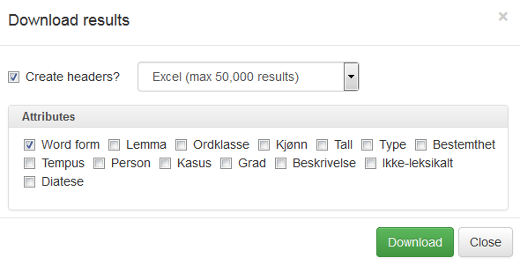
Klikker du på Download-knappen over søkeresultatene (se figur 2), får du opp en dialogboks der du kan velge flere nedlastingsformater: Excel-fil, tabseparert tekstfil eller kommaseparert tekstfil. Du kan også velge hvilken informasjon som skal lastes ned, se figur 21.
Figur 21: Vinduet for nedlastingsalternativer.
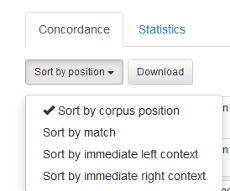
1.7 Sorter søkeresultatene
Søkeresultatene kan sorteres på ulike måter slik figur 22 viser: Dersom du vil sortere etter søkeordet, velger du Sort by match. Du kan også sortere etter ordet umiddelbart til venstre eller ordet umiddelbart til høyre. Legg merke til at skilletegn blir alfabetisert før a og b osv.
Figur 22: Søkeresultatene kan sorteres på ulike måter.