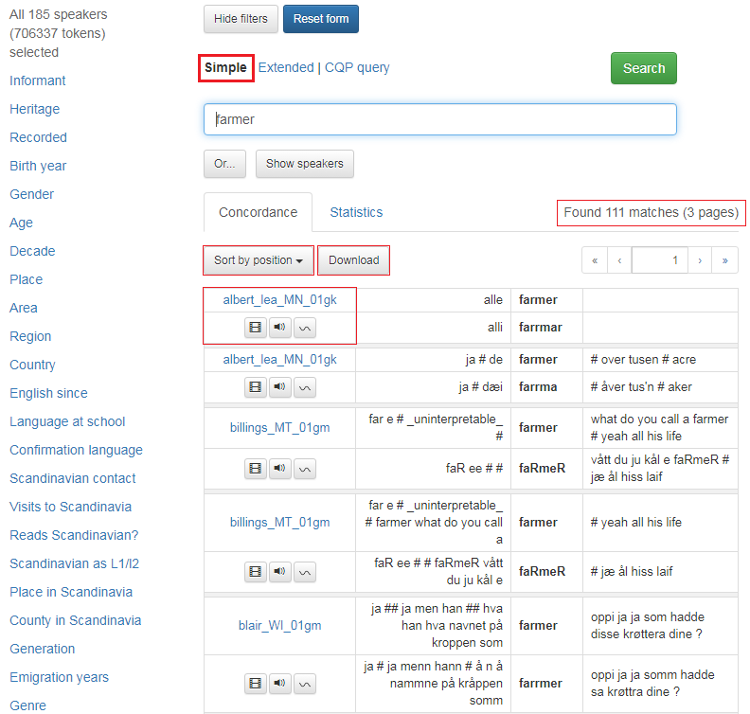
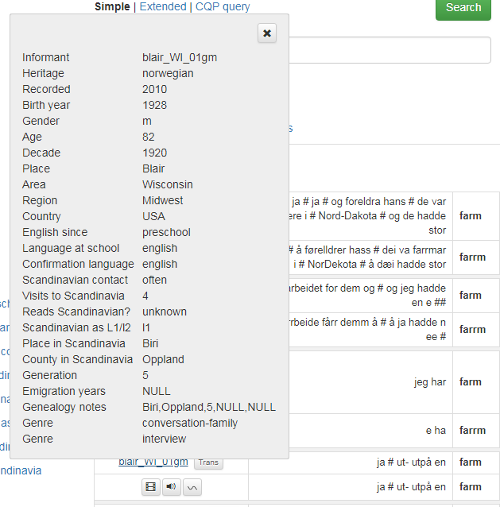
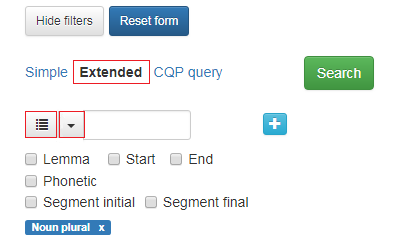
Figur 1 viser hovedsøkesiden til CANS:
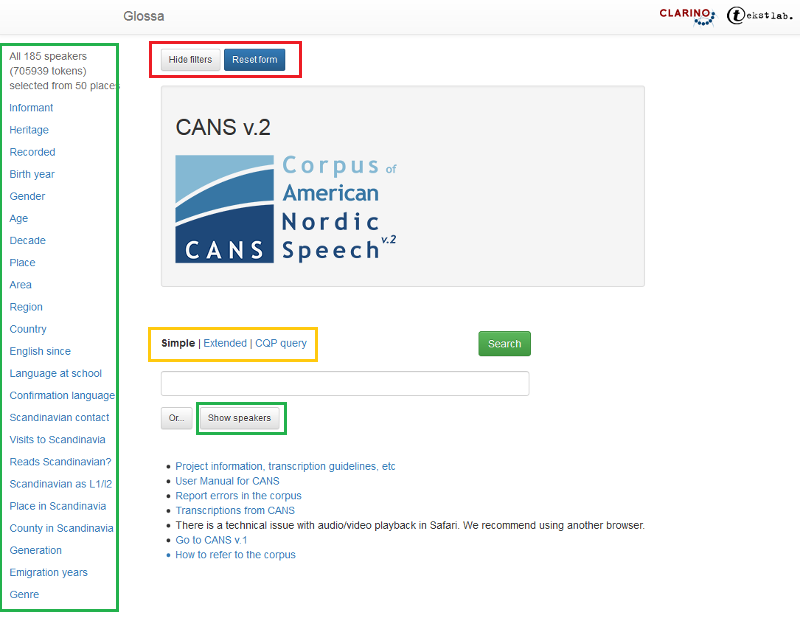
Figur 1: Hovedsøkesiden CANS.
Brukerveiledning for CANS - amerikanordisk talespråkskorpus
Gå til hjemmesiden
English version
CANS - amerikanordisk talespråkskorpus - har fått nytt søkegrensesnitt: https://tekstlab.uio.no/glossa3/cans3
Denne nye versjonen av søkegrensesnittet
Glossa er i hovedsak lik den gamle, men har noen nye funksjoner.
Se hvordan du kan bruke den nye versjonen av Glossa i to instruksjonsvideoer:
Denne brukerveiledningen er skrevet for den gamle versjonen av søkegrensesnittet: https://tekstlab.uio.no/glossa2/cans3
Kontakt tekstlab-post@iln.uio.no om du har spørsmål.
Brukerveiledningen er skrevet av Kristin Hagen og Ingvild Røsok. Veiledningen bygger på The Nordic Dialect Corpus - Search Interface Documentation skrevet av Eirik Olsen.
1. CANS - Amerikanordisk talespråkskorpus v.2
CANS v.2 består av intervjuer og samtaler med 163 amerikanorske informanter fra 44 steder i USA og Canada, i tillegg til 22 svenskamerikanske informanter fra sju steder i USA.
På denne siden:
1.1 Transkripsjonene i CANS
1.2 Hovedsøkesiden til CANS
1.2.1 Enkelt søk (simple) og eksempel på resultatvisninger
1.2.2 Utvidet søk (Extended)
1.2.2.1 Søk på flere ord
1.2.2.2 Søk på Lemma, Start, End, Segment initial, Segment final eller Phonetic
1.2.2.3 Søk på ordklasse eller morfologiske trekk
1.2.2.4 Søk på andre tagger (latter, ord som ikke står i ordboka osv)
1.2.2.5 Spesifiser eller ekskluder lemma og ordform
1.2.3 CQP-søkeuttrykk (CQP query)
1.2.4 Eller-søk (Or)
1.3 Metadatasøk og Show speakers
1.4 Tilfeldig utvalg av søkeresultatene
1.5 Kart
1.6 Statistikk
1.7 Last ned data
1.1 Transkripsjonene i CANS
Opptakene er blitt transkribert både lydnært og ortografisk, de første transkripsjonene ved hjelp av transkripsjonsprogrammet Transcriber, senere med transkripsjonsprogrammet Elan. Transkripsjonsverktøyene kobler også transkripsjonene sammen med lydfilene.
Opptakene er transkribert ord for ord uten å endre ordstillingen. CANS er transkribert etter de samme retningslinjene som Nordisk dialektkorpus. Les denne transkripsjonsveiledningen her. I tillegg er det laget noen egne retningslinjer for transkripsjon og translitterering for norsk i Amerika. Svensk i Amerika har også noen tillegg til retningslinjene du kan lese her.
Intervjuene og samtalene i korpuset har blitt transkribert på to måter: en lydnær transkripsjon og en ortografisk transkripsjon. Transkripsjonene er koblet sammen og er også koblet til de originale lyd- og videofilene.
1.2 Hovedsøkesiden til CANS
Figur 1 viser hovedsøkesiden til CANS:
Figur 1: Hovedsøkesiden CANS.
Til venstre er alle metadatakategoriene det går an å søke i. I CANS er dette forskjellige egenskaper hos informantene: Informant, Heritage, Recorded, Birth year, Gender, Age, Decade, Place, Area, Region, Country, English since, Language at school, Conformation language, Scandianivan contact, Visits to Scandinavia, Reads Scandinavian?, Scandinavian as L1/l2, Place in Scandinavia, County in Scandinavia, Generation, Emigration years, Genre.
Du ser hvor mange informanter som er valgt over metadatakategoriene.
Knappen Show speakers gir deg en oversikt over alle informantene eller det utvalget informanter du har valgt. Les mer under 1.3.
Øverst er to knapper. Med Hide filters kan du skjule metadatakategoriene til venstre.
Reset form gir deg en blank søkeside. Resten av søkesiden handler om søkeordet eller egenskaper ved det. Les mer nedenfor.
1.2.1 Enkelt søk (simple) og eksempel på resultatvisninger
I enkelt søk (Simple) kan du søke på enkeltord og fraser i søkefeltet. Resultatene vises som en konkordans (se figur 2). Du kan se antall treff over søkeresultatene til høyre. Det presenteres 50 søkeresultater per side. Er det flere, presenteres de over flere sider som man kan klikke seg inn på.
Over søkeresultatene finner du knapper for nedlasting og sortering, se 1.7. og 1.8. Søkeresultatvisningen Concordance er den forhåndsvalgte visningen, men du kan også få ulike statistiske visninger av søkeresultatet, se 1.6. for statistikk eller 1.5. for geografisk kart.
Dersom du holder musa over ordet, får du opp et lite vindu med informasjon om lemma, ordklasse, annen morfologisk informasjon og tagger, se figur 3. Les mer om ordklasser og tagger i 1.2.2.3 og 1.2.2.4.
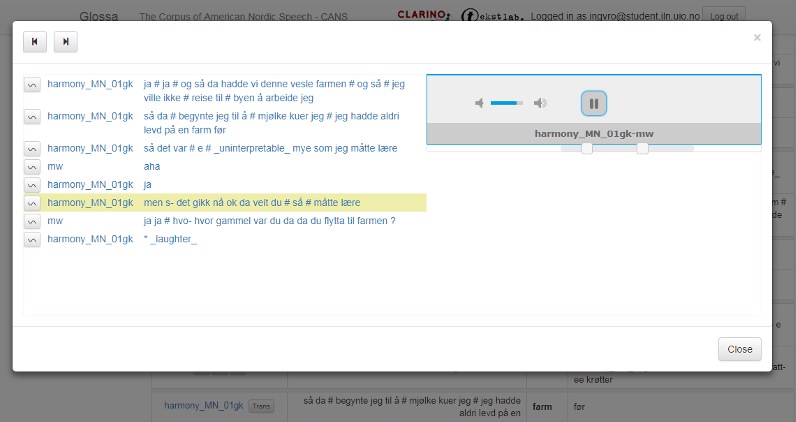
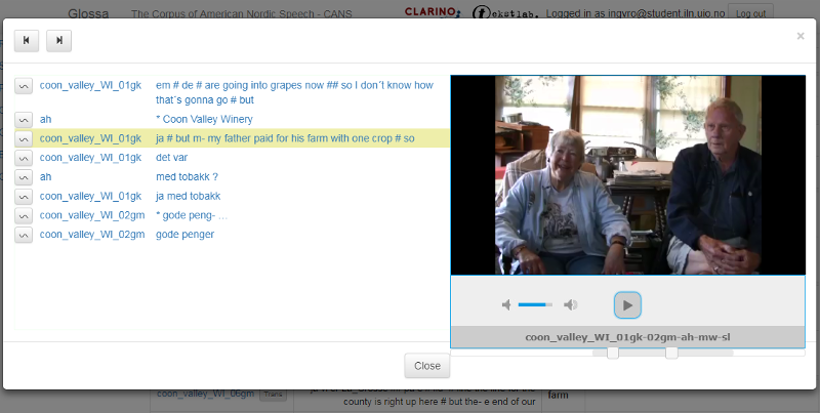
Til venstre for søkeresultatene er det tre ikoner. Klikk på lydikonet for å få opp lyd (se figur 4). Klikk på videoikonet for å spille av video (figur 5). Merk at ikke alle opptakene har videoopptak. I avspillingsboksen kan man få mer kontekst ved å dra firkantene under boksen til venstre og/eller høyre.
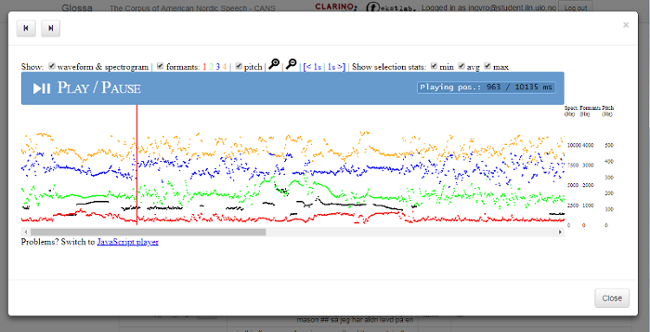
Klikk på det tredje ikonet for å få opp lydbølge og spektrogram for søkeresultatet (se figur 6). Klikk på informantnummeret for å få opp metadata om informanten (se figur 7).
I søkeresultatet står den ortografiske transkripsjonen over den originale, lydnære CANS-transkripsjonen.
Figur 2: Søkeresultat for enkeltord i talekorpuset.
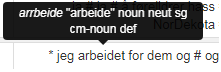
Figur 3: Dersom du holder musa over et ord i søkeresultatet, får du opp et lite vindu med informasjon om lemma, ordklasse, annen morfologisk informasjon og tagger. I CANS ser du også den fonetiske transkripsjonen om den finnes.
Figur 4: Lydavspilling av søkeresultatet.
Figur 5: Videoavspilling av søkeresultatet.
Figur 6: Lydbølge og spektrogram.
Figur 7: Metadata om informanten.
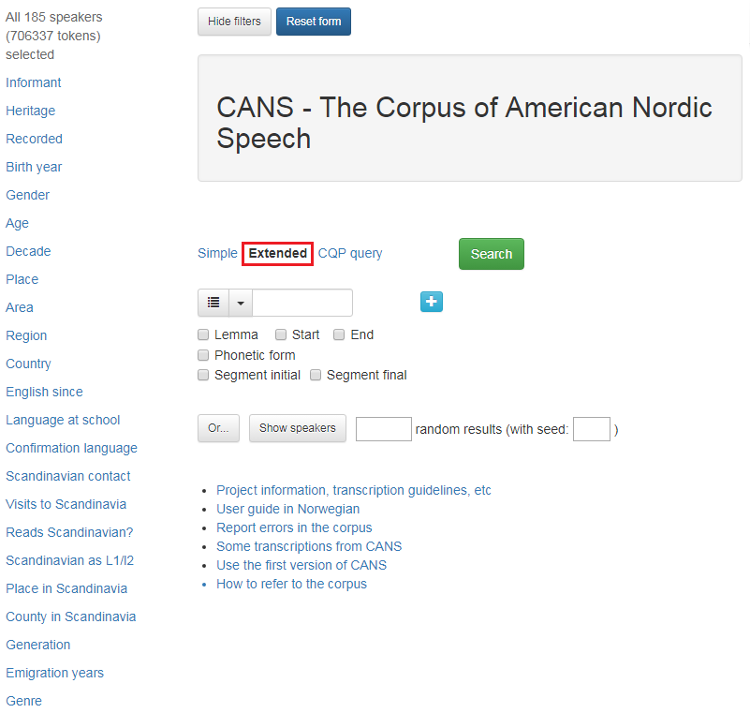
1.2.2 Utvidet søk (Extended)
Utvidet søk (se figur 8) gir flere søkemuligheter. Du kan søke både på både enkeltord og fraser, på lemma, starten eller slutten på ord, på lydnær stavemåte eller på begynnelsen eller slutten på et segment. Velger du Phonetic, vil du kun få resultater fra den lydnære transkripsjonen. Du kan også søke på ordklasser, morfologiske trekk eller andre tagger.
1.2.2.1 Søk på flere ord
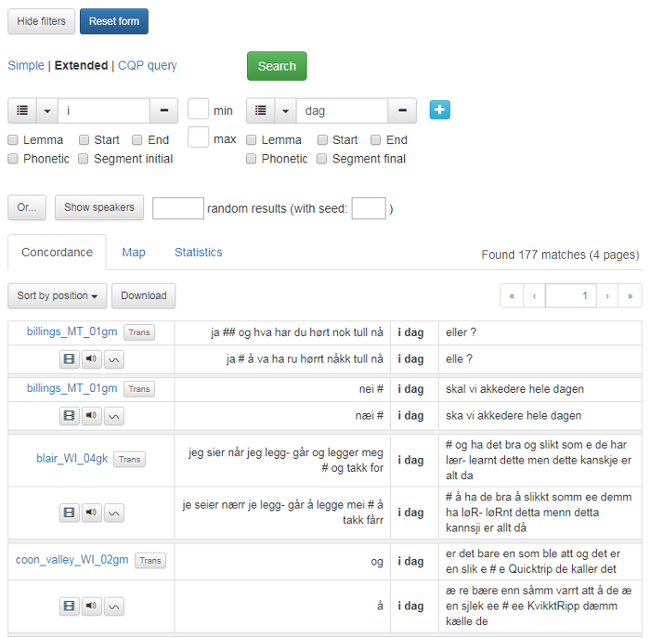
Dersom du fyller inn noe i den første søkeboksen og klikker på det blå plusstegnet til høyre, får du opp en søkeboks til. Du kan lage så mange søkebokser du vil. Mellom søkeboksene kan du definere hvor mange ord det minimum eller maksimum skal være mellom søkeordene. Du fjerner en søkeboks ved å klikke på minustegnet til høyre i boksen.
I figur 9 er det gjort et søk på frasen i dag. Det er funnet 177 resultater som presenteres over 4 sider. Klikk på pilene for å navigere i søkeresultatene.
Figur 9: Søk på flere ord.
1.2.2.2 Søk på Lemma, Start, End, Segment initial, Segment final eller Phonetic
Under søkevinduet er det fem bokser der man kan krysse av for Lemma, Start, End, Segment initial, Segment final eller Phonetic. Dersom du krysser av for Lemma, får du alle bøyingsformer av et ord som resultat, for søkeordet bok får du både bok, boka, boken, bøker og bøkene som resultat dersom ordene finnes i korpuset.
Krysser du av for Start eller End, får du alle ordene som enten begynner eller starter med ordet eller bokstavene som står i søkeboksen. Et søk på bok der Start er krysset av, kan gi resultater som bokklubb eller bokstaver. Er End krysset av, kan resultatene være ord som lesebok eller baseballbok.
Når du skriver et ord inn i søkefeltet, vil du søke i den ortografiske delen av korpuset. Et kryss i Phonetic gjør at du søker direkte i den talemålsnære delen av korpuset. Dette kan være nyttig hvis du ser etter fonetiske varianter av et ord, som for eksempel variantene itte eller ikkje av ordet ikke. I figur 2 er farmer blant annet uttalt faRmeR. Søker du på faRmeR og krysser av for Phonetic, får du 5 treff. Du kan søke i fonetisk og ortografisk versjon samtidig. Les om dette i 1.2.2.5.
Transkripsjonene i CANS består av segmenter og ikke setninger i skriftspråklig forstand. Segmentene er skilt fra hverandre, ikke med punktum, men med tidskoder som angir hvor i videoen eller lydfila segmentet starter eller stopper. Segmentene vil ofte tilsvare skriftspråklige setninger, men siden dette er talemål, kan det også være snakk om ufullstendige setninger uten subjekt og finitte verbal.
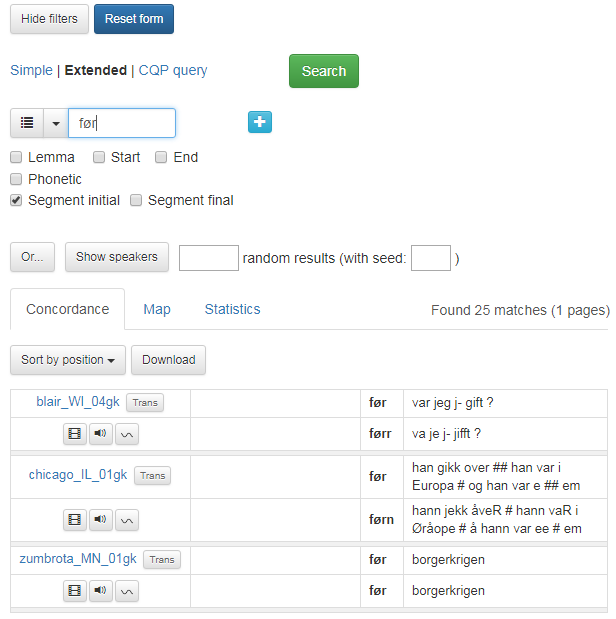
Krysser du av for Segment initial, spesifiserer du at søkeuttrykket skal komme først i et segment. Et kryss i Segment final betyr søk på det siste ordet. Figur 10 viser et søk på ordet før i Segment initial.
Figur 10: Før i Segment initial-posisjon.
1.2.2.3 Søk på ordklasse eller morfologiske trekk
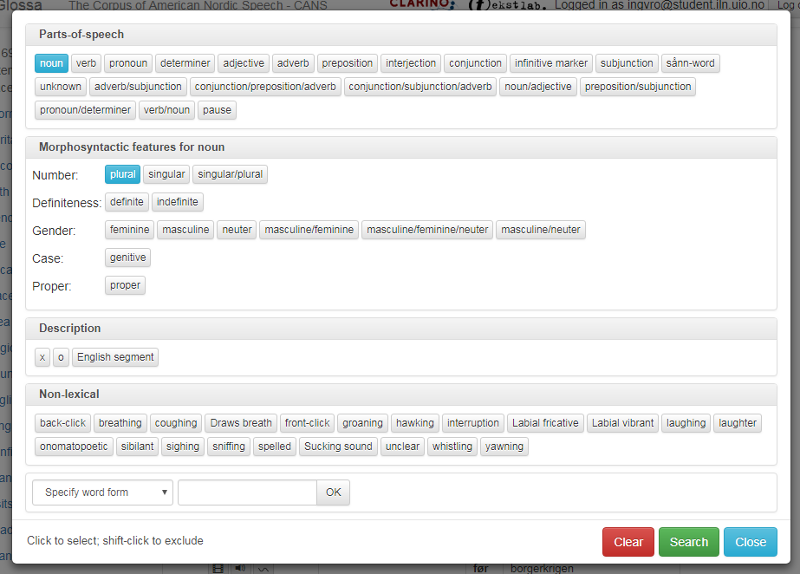
I utvidet søk kan du søke på ordklasse ved å bruke nedtrekksmenyen som skjuler seg bak pilen til venstre i søkeboksen, se figur 11. Klikker du på knappen til venstre for pilen, får du opp boksen i figur 12. Velger du en ordklasse under Parts-of-speech, får du også tilgang til valgene under Morphosyntactic features for den ordklassen du har valgt. Valgene dine kommer opp i små blå bokser under søkefeltet. I figur 11 er det søkt på Substantiv flertall.
De andre avkryssingsmulighetene i boksen på figur 12 blir forklart i kapitlene under.
Figur 11: Knappene for ordklassesøk og søk etter andre morfologiske trekk.
Figur 12: Søk på ordklasse og annen morfologisk informasjon.
Hvis du klikker på flere ordklasser samtidig, for eksempel både substantiv og pronomen, vil du få treff på alle ordene som er enten substantiv eller pronomen.Tilsvarende kan du klikke på flere verdier innafor en kategori, for eksempel både hunkjønn og hankjønn i kjønn-kategorien under substantiv for å få treff på substantiv som er enten hunnkjønn, hannkjønn eller begge deler.
1.2.2.4 Søk på andre tagger (latter, ord som ikke står i ordboka osv.)
Under Description og Non-lexical i søkeboksen beskrevet i 1.2.2.3 ovenfor (figur 12) kan du søke på tagger som enten beskriver ordene eller som er selvstendige hendelser i talestrømmen:
Under Description i søkefeltet kan du søke etter disse tre taggene:
X: Opptakene har blitt transkribert ortografisk med Bokmålsordboka (2005) som retningslinje. X-taggen er brukt på ord som ikke finnes i ordboka, men som finnes i segmenter hvor norsk er hovedspråket. Ordene som er merket X kan være engelske ord, dialektord eller andre ord som ikke finnes i ordboka..
O: Brukt i tilfeller hvor grammatiske ord som ikke finnes i den ortografiske standarden, er "oversatt" til standardversjonen.
Eng: En engelsk sekvens hvor opptil flere ord blir sagt på engelsk.
Under Non-lexical i søkefeltet kan du søke etter disse taggene:
Back-click, breathing, coughing, draws breath, front-click, groaning, hawking, interruption, labial fricative, labial vibrant, laughing, laughter, onomatopoetic, sibilant, sighing, sniffing, spelled, sucking sound, unclear, whistling og yawning.
Dette er selvstendige hendelser, hvor mesteparten av dem er ikke-leksikalske ytringer som latter eller hosting.
Interruption blir brukt når en informant avryter seg selv eller blir avbrutt av en intervjuer eller annen informant.
Unclear words er ord som er utydelige eller på andre måter uklare for transkribøren som jobbet med transkripsjonen.
Spelled words brukes når et ord staves.
Laughing er ord som blir sagt mens man ler, mens laughter markerer ikke-leksikalsk latter.
Whispering/singing/yawning er ord som blir hvisket, sunget eller som blir sagt mens man gjesper.
Krysser du av for én eller flere av taggene ovenfor, får hendelsen selv - for eksempel latter - som resultat.
I figur 13 er det søkt etter ord som er merket som eng for engelsk segment. Merk at fordi søkeresultatet kun viser et uthevet ord om gangen og ikke hele segmentet, kan det være nyttig å bruke lydfunskjonen til å få en oversikt over konteksten og segmentet i sin helhet.
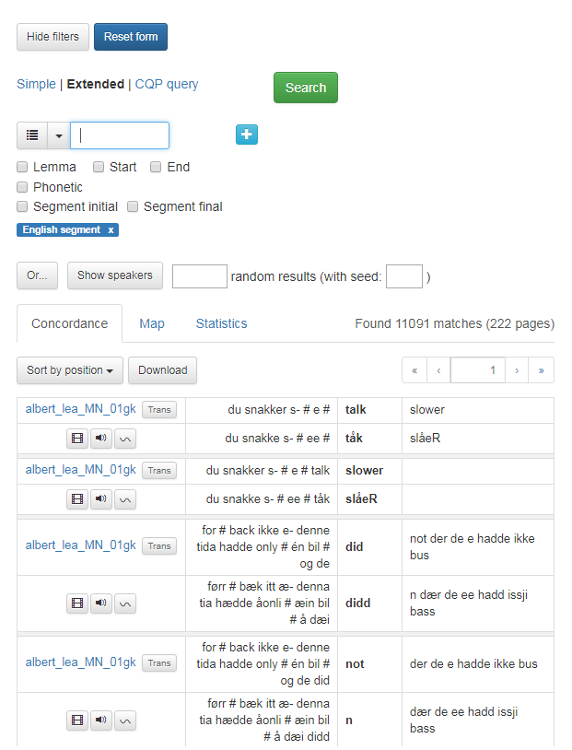
Figur 13: Søk på ord som er merket med eng for engelsk.
1.2.2.5 Spesifiser eller ekskluder lemma og ordform
Nederst i
den morfologiske søkeboksen i figur 11 er det et felt der du ytterligere kan spesifisere et søk. Velger du for eksempel verb i den morfologiske søkeboksen, men bare er ute etter hjelpeverbene, kan du velge Specify lemma og legge til hjelpeverbene ett for ett i boksen til høyre og trykke OK mellom hver gang.
Dersom du har valgt verb, men ikke vil ha med hjelpeverbene, gjør du det på samme måte, men velger Exclude word form eller lemma.
Har du valgt å søke etter Phonetic som beskrevet i 1.2.2.2, kan du spesifisere hvilke ortografisk ordform eller lemma ordet skal ha i Specify word form eller lemma. Søk for eksempel på Phonetic og je og Specify word form jeg, og du får alle tilfeller der jeg uttales som je.
NB! Husk å klikke på OK når du har skrevet inn et ord i boksen! Ord som er ekskludert, vil da komme opp på høyre side i rødt med et utropstegn foran, se figur 14 og figur 16. Ord som er spesifisert, kommer opp i blått.
Figur 14: Spesifiser eller ekskluder lemma og ordform.
1.2.3 CQP-søkeuttrykk (CQP query)
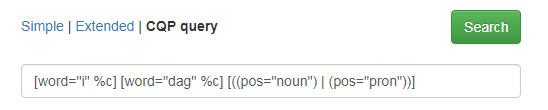
CQP-søkeuttrykk kan brukes til avanserte søk som ikke er mulige i enkelt eller utvidet søk. For å bruke denne muligheten må du kunne CQP-søkespråket. Om du trenger hjelp til et avansert søk, kan du ta kontakt med Tekstlaboratoriet. Figur 15 viser et eksempel på hvordan søk etter ordene i dag etterfulgt av substantiv eller pronomen ser ut i enten utvidet søk (Extended) eller i CQP query. Dersom du har brukt mulighetene i Extended search og lurer på hvordan dette søket ser ut på CQP-søkespråket, klikker du på CQP query, så får du opp søkeuttrykket som i figur 15.
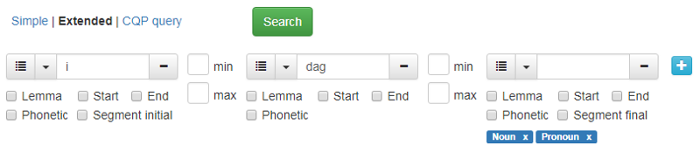
Figur 15: Eksempel på samme søk i Extended og CQP query
1.2.4 Eller-søk (Or)
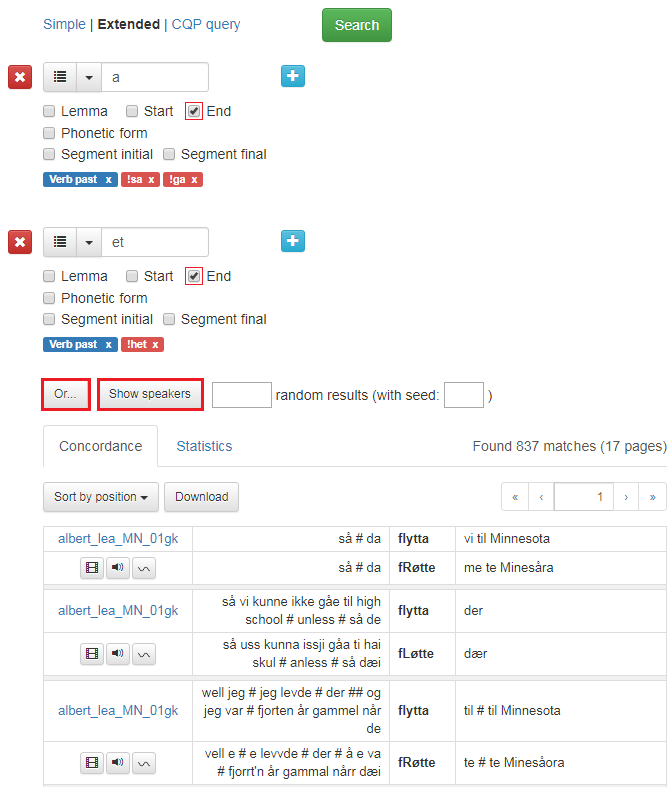
Ved å klikke på Or-boksen får du opp et nytt søkevindu under det andre. Søk i denne boksen gir et eller-søk. Det vil si at du søker på ordet i hovedsøkeboksen eller ordet i Or-boksen. Du kan lage så mange Or-bokser du vil, og du sletter dem ved å klikke på det røde krysset til venstre for boksen.
Figur 16 viser et komplisert søk etter verb i preteritum som ender på enten -a eller -et. Verbene sa, ga og het er ekskludert.
Figur 16: Or-søk.
1.3 Metadatasøk og Show speakers
Til venstre i søkeskjemaet er alle metadatakategoriene ramset opp. For CANS er kategoriene: Informant, Heritage, Recorded, Birth year, Gender, Age, Decade, Place, Area, Region, Country, English since, Language at school, Conformation language, Scandianivan contact, Visits to Scandinavia, Reads Scandinavian?, Scandinavian as L1/l2, Place in Scandinavia, County in Scandinavia, Generation, Emigration years, Genre.
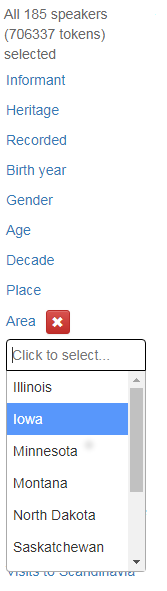
Klikker du på en av lenkene, kommer de ulike verdiene i hver kategori opp. Du kan klikke på og velge én eller flere, og valget du gjør, blir synlig i en boks under kategorien. Klikker du på det røde krysset, blir valget nullstilt. Figur 17 viser hvordan metadatamenyen ser ut når man har klikket på kategorien Area.
Figur 17: Metadatamenyen der det er klikket på Area.
Valget du gjør, begrenser de videre mulighetene du har for søk. Har du valgt for eksempel F i kategorien Kjønn, vil du bare kunne velge verdier som er knyttet til de kvinnelige informantene. For eksempel vil du ikke få valget Iowa under Area. I figur 18 er det krysset av for Illinois under Area.
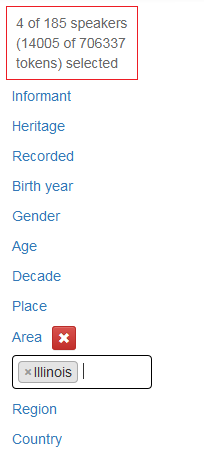
Figur 18: Illinois er valgt under Area.
Over metadatakategorimenyen er det en teller som til enhver tid viser deg hvor mange informanter du har valgt og hvor mange tokens utvalget da består av. I denne versjonen inneholder CANS 185 informanter og 706 337 tokens (ord og skilletegn) slik figurene ovenfor viser. Når det er valgt bare informanter som er fra Illinois, begrenser utvalget seg til 4 informanter og 14005 tokens slik figur 18 viser.
Dersom du ønsker å se en samlet oversikt over informantene du har valgt, klikker du på Show speakers-knappen nedenfor ordsøkeboksen ved siden av Or-knappen, se figur 16. Resultatet blir som i figur 19 for utvalget fra figur 18.
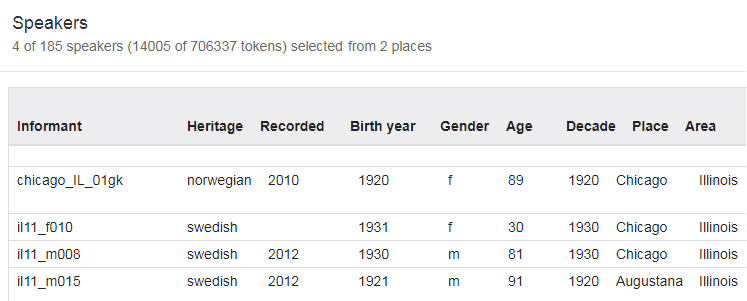
Figur 19: Show speakers-vinduet.
De ulike metadatakategoriene er kort beskrevet nedenfor:
Informant: Hver informant har fått tildelt en informantkode i stedet for sitt virkelige navn.
For de norske informantene består denne koden av stedsnavn, stat (postkodeforkortelse), et tall og forkortelsen gk, gm, uk eller um (gammel kvinne/mann, ung kvinne/mann). For de svenske består koden av stat (postkodeforkortelse), innspillingsår, forkortelsen f eller m for kvinne eller mann og et nummer.
Du kan søke på én eller flere informantkoder.
Heritage: Informantens opphav. Her kan du velge mellom norsk eller svensk.
Recorded: Årsstallet opptaket ble spilt inn.
Age, Birth year and Gender: Informantens kjønn, alder og fødselsår.
Decade: Det tiåret informanten ble født.
Place: Byen/stedet informanten er fra.
Area: Delstaten/provins informanten er fra.
Region: Regionen informanten kommer fra. Her kan du velge mellom fem alternativer.
Country: Landet informanten kommer fra. Her kan du velge mellom USA eller Canada.
English since: Tidspunkt for når informanten lærte engelsk.
Language at school: Hvilket språk som ble brukt i skolen.
Conformation language: Hvilket språk informanten ble konfirmert på.
Scandianivan contact: Hvor mye kontakt informanten har hatt med Skandinavia.
Visits to Scandinavia: Antall ganger informanten har vært i Skandinavia.
Reads Scandinavian?: Om informanten leser skandinavisk.
Scandinavian as L1/l2: Om informanten har skandinavisk som første- eller andrespråk.
Place in Scandinavia: Hvor informantens forferdre og familie kommer fra i Skandinavia.
County in Scandinavia: Fylke/len informantens forferdre er fra.
Generation: Antall generasjoner siden informantens forfedre immigrerte. Det kan også være informanten selv som immigrerte.
Emigration years: Årstall for når informanten/informantens forfedre immigrerte.
Hver informant har flere forfedre, men det er som regel ikke gitt informasjon om alle forfedrene. Informasjonen om hver enkelt slektning er adskilt med semikolon for Place in Scandinavia, County in Scandinavia, Generation og Emigration years.
Genre: Hvilken opptaksform. Her kan du velge mellom intervju eller samtale.
Les mer om informantene på hjemmesiden til CANS.
1.4 Tilfeldig utvalg av søkeresultatene
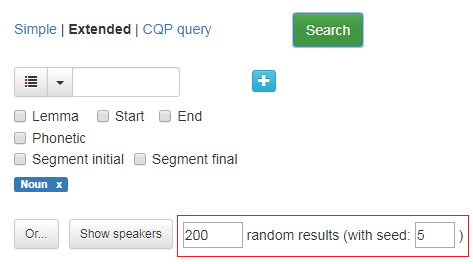
Dersom man har et søk som vil gi mange treff, kan man velge å få se bare et visst antall tilfeldig utvalgte treff. Spesifiser antall treff i boksen ved siden av Show speakers.
Dersom du vil gjenskape akkurat dette resultatet senere, velger du et tall og setter det inn i boksen with seed. I figur 20 er er det søkt etter alle substantiv i korpuset, med en visning på 200 tilfeldig utvalgte treff. Tallet 5 er skrevet i with seed-boksen. Hver gang du gjør det samme søket og skriver det samme tallet i boksen, får du det samme tilfeldige utvalget av søkeresultatene. Skriver du et annet tall, får du et annet tilfeldig utvalg.
Det er mulig å velge tilfeldig utvalg av søkeresultatene for søk som er Extended eller CQP query.
Figur 20: Avkrysningsboks for å få et tilfeldig utvalg av søkeresultatene, her med 200 tilfeldige resultater.
1.5 Kart
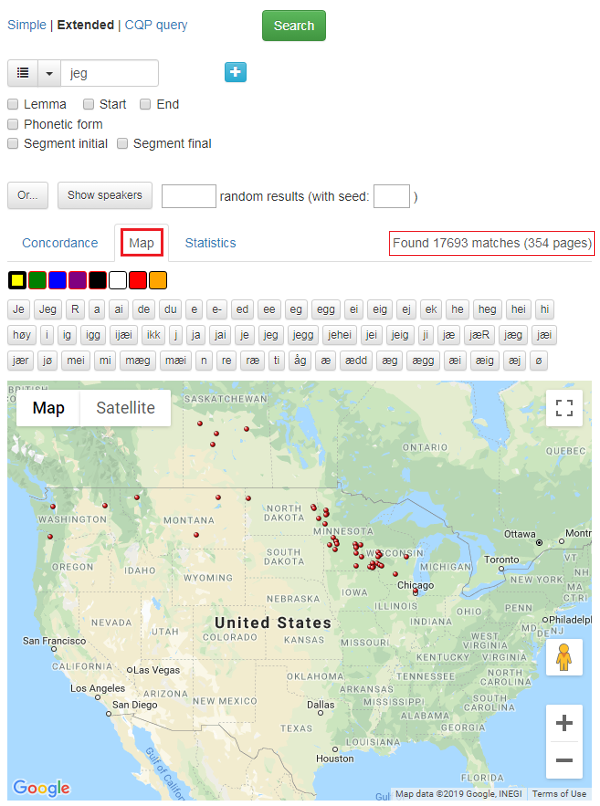
Søkeresultatvisningen Concordance er den som er forhåndsvalgt og som alle eksemplene ovenfor er hentet fra. Velger du Map som vist i figur 21 nedenfor, kan du få en kartlig oversikt over utbredelsen av et ord og dets varianter i korpuset. Du kan zoome inn ut og på kartet for å få bedre oversikt.
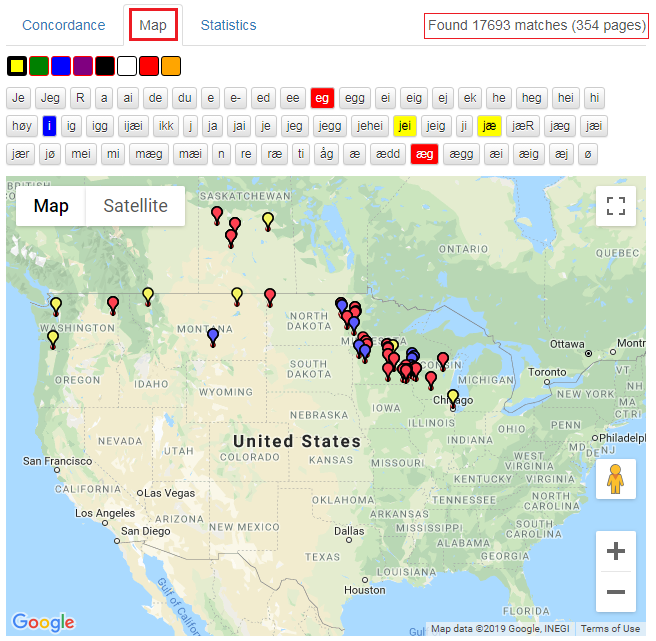
I figur 21 har det blitt gjort et søk etter ordet jeg. De røde prikkene på kartet markerer hvor informantene som har brukt ordet, kommer fra.
Figur 21: Kart som viser varianter av et søkeord og hvor de er brukt.
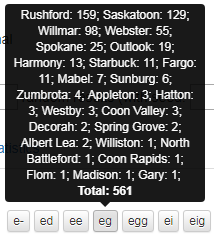
Ved å holde musepekeren over en variant, som i figur 22, får du opp et vindu med informasjon om hvilke steder varianten er brukt, antall ganger den er brukt på hvert sted, samt antall treff for varianten totalt. Antall treff for alle variantene sammenlagt finner du i høyre hjørne over kartet, se figur 23.
Figur 22: Viser fordelingen av et ords varianter og antall som er registrert på hvert sted.
Ved å klikke på en farge og deretter på en variant, kan du se variantens utbredelse på kartet. I figur 23 under er tre av variantene markert med fargene rød, blå og gul. For å fjerne fargen klikker du en eller to ganger på boksen til boksens farge blir grå igjen.
Figur 23: Du kan bruke fargene for å se utbredelsen av variantene.
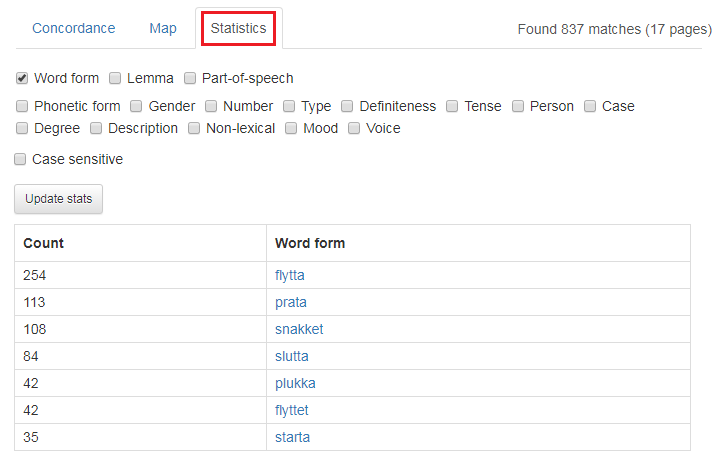
1.6 Statistikk
Søkeresultatvisningen Concordance er den som er forhåndsvalgt og som alle eksemplene ovenfor er hentet fra. Velger du Statistics som i figur 24 nedenfor, kan du be om ulike frekvenstellinger og statistikk. Foreløpig er det boksene over Update stats som kan velges. Klikk av for hva du vil se, og trykk Update stats. Eksempel 20 viser frekvenser fra søket i figur 16, altså søk etter verb i preteritum som ender på enten -a eller -et. Verbene sa, ga og het er ekskludert. Frekvensene er til venstre og ordformen til høyre.
Figur 24: Statistikkvisning for søkeresultatet fra figur 16.
1.7 Last ned data
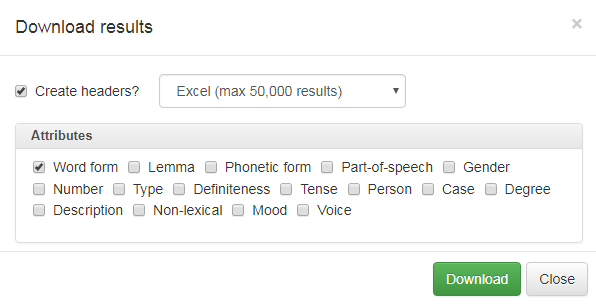
Klikker du på Download-knappen over søkeresultatene (se figur 2), får du opp en dialogboks der du kan velge flere nedlastingsformater: Excel-fil, tabseparert tekstfil eller kommaseparert tekstfil. Du kan også velge hvilken informasjon som skal lastes ned, se figur 25.
Figur 25: Vinduet for nedlastingsalternativer.
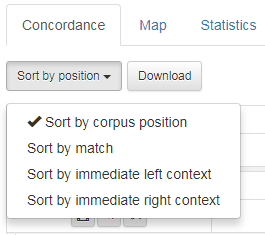
1.8 Sorter søkeresultatene
Søkeresultatene kan sorteres på ulike måter slik figur 26 viser: Dersom du vil sortere etter søkeordet, velger du Sort by match. Du kan også sortere etter ordet umiddelbart til venstre eller ordet umiddelbart til høyre. Legg merke til at skilletegn blir alfabetisert før a og b osv (se figur 27).
Figur 26: Søkeresultatene kan sorteres på ulike måter.
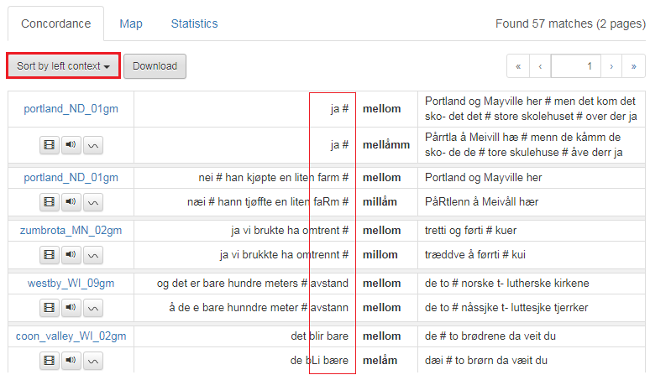
Figur 27: Skilletegn og andre symboler blir alfabetisert før a og b.