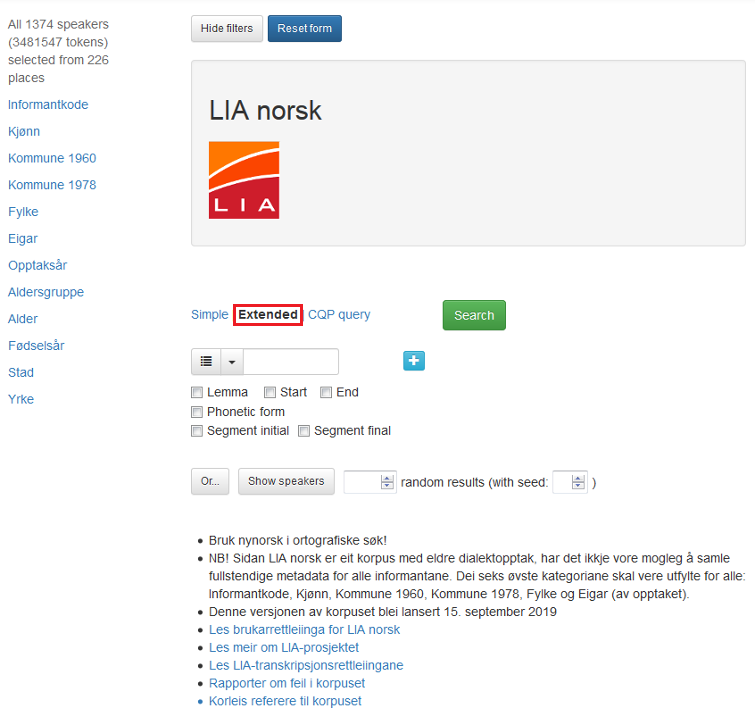
Figur 1 viser hovudsøkjesida til LIA norsk:
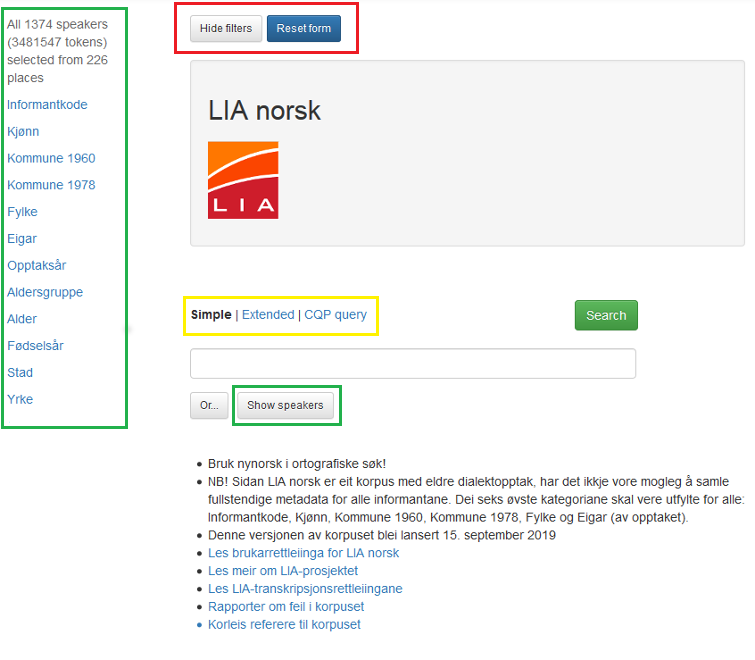
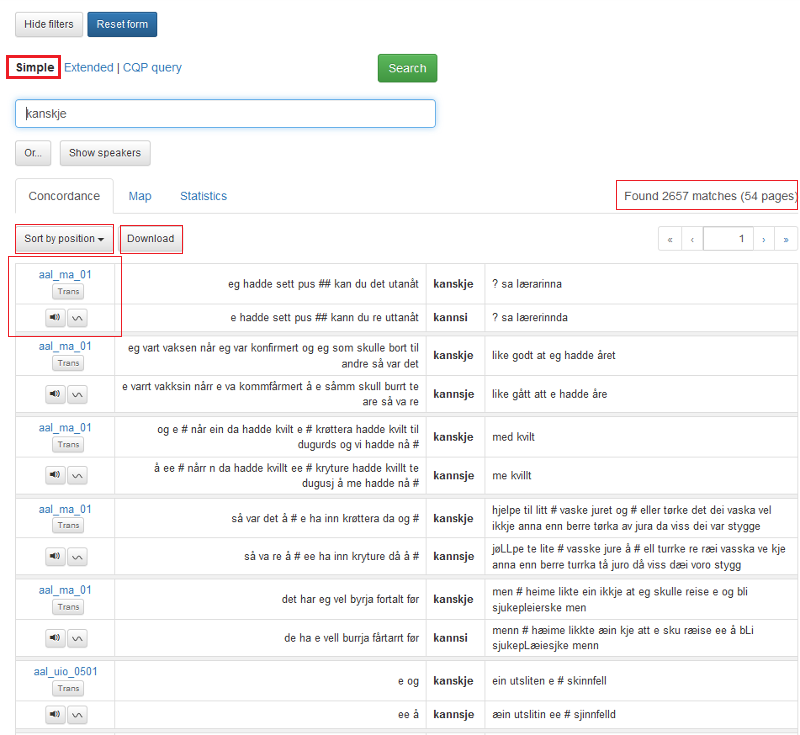
Figur 1: Hovudsøkjesida til LIA norsk.
Brukarrettleiing for LIA norsk - korpus av eldre dialektopptak
LIA norsk - korpus av eldre dialektopptak har fått nytt søkegrensesnitt: https://tekstlab.uio.no/glossa3/lia_norsk
Denne nye versjonen av søkegrensesnittet
Glossa er i hovedsak lik den gamle, men har nokre nye funksjonar.
Sjå korleis du kan bruke den nye versjonen av Glossa i to instruksjonsvideoar:
Denne brukarrettleiinga er skriven for den gamle versjonen av søkegrensesnittet: https://tekstlab.uio.no/glossa2/lia_norsk
Kontakt tekstlab-post@iln.uio.no om du har spørsmål.
Brukarrettleiinga er skriven av Kristin Hagen og Ingvild Røsok. Rettleiinga bygger på The Nordic Dialect Corpus - Search Interface Documentation skriven av Eirik Olsen.
LIA norsk v.1.1 består av opptak og transkripsjonar med 1382 informantar frå 227 stader i Noreg, ca 3,5 millionar ord eller einingar. Opptaka kjem frå fire universitet: Universitetet i Oslo, Universitetet i Bergen, UiT - Noregs arktiske universitet og Noregs teknisk-naturvitskaplege universitet. Opptaka er digitaliserte ved Nasjonalbiblioteket i Mo i Rana.
Versjon 1.1 blei publisert i januar 2022. I denne versjonen er det retta nokre feil i metadata. Dessutan er desse informantane lagt til:
kristiansand_uib_0101 kristiansand_uib_0102 samnanger_uib_0101 samnanger_uib_0102 stemshaug_ntnu_0201 ulstein_uib_0101 ulstein_uib_0102 vefsn_ntnu_0101
Første versjon av LIA norsk blei lansert 15. september 2019.
På denne sida:
1.1 Transkripsjonane i LIA norsk
1.2 Hovudsøkjesida til LIA norsk
1.2.1 Enkelt søk (simple) og eksempel på resultatvisningar
1.2.2 Utvida søk (Extended)
1.2.2.1 Søk på fleire ord
1.2.2.2 Søk på Lemma, Start, End, Segment initial, Segment final eller Phonetic form
1.2.2.3 Søk på ordklasse eller morfologiske trekk
1.2.2.4 Søk på andre taggar (latter, ord som ikkje står i ordboka osv)
1.2.2.5 Spesifiser eller ekskluder lemma og ordform
1.2.3 CQP-søkjeuttrykk (CQP query)
1.2.4 Eller-søk (Or)
1.3 Metadatasøk og Show speakers
1.4 Tilfeldig utval av søkjeresultata
1.5 Kart
1.6 Statistikk
1.7 Last ned data
1.1 Transkripsjonane i LIA norsk
Opptaka er blitt transkriberte lydnært og ortografisk ved hjelp av transkripsjonsprogrammet ELAN. Her blir transkripsjonane også kopla saman med lydfilene. Opptaka blir først transkriberte lydnært. Deretter blir transkripsjonane translittererte til ein ortografisk variant, ord for ord utan å endre ordstillinga, med den halvautomatiske Oslo-translitteratoren. Til slutt blir alle transkripsjonane korrekturlesne saman med lyden. Sluttresultatet er ELAN-filer der både den talemålsnære og den ortografiske transkripsjonen er synleg. Begge variantane blir tatt inn i korpuset.
Les transkripsjonsrettleiinga for LIA norsk og translittereringsveiledninga for LIA norsk.
1.2 Hovudsøkjesida til LIA norsk
Figur 1 viser hovudsøkjesida til LIA norsk:
Figur 1: Hovudsøkjesida til LIA norsk.
Til venstre er alle metadatakategoriane det går an å søkje i. I LIA norsk er dette forskjellige eigenskapar hos informantane eller opptaket: Informantkode, Kjønn, Kommune 1960, Kommune 1978, Fylke, Eigar, Opptaksår, Aldersgruppe, Alder, Fødselsår, Stad, Yrke.
Du ser kor mange informantar som er valt over metadatakategoriane.
Knappen Show speakers gir deg ein oversikt over alle informantane eller det utvalet informantar du har valt. Les meir under 1.3.
NB! Sidan LIA norsk er eit korpus med eldre dialektopptak, har det ikkje vore mogleg å samle fullstendige metadata for alle informantane. Dei seks øvste kategoriane skal vere utfylte for alle: Informantkode, Kjønn, Kommune 1960, Kommune 1978, Fylke og Eigar.
Øvst er to det knappar. Med Hide filters kan du skjule metadatakategoriane til venstre.
Reset form gir deg ei blank søkjeside.
Resten av søkjesida handlar om søkjeordet eller eigenskapar ved det. Les meir nedanfor.
1.2.1 Enkelt søk (Simple) og eksempel på resultatvisningar
I enkelt søk (Simple) kan du søkje på enkeltord og fraser i søkjefeltet. Resultata blir viste som ein konkordans (sjå figur 2) med den ortografiske transkripsjonen over den originale, lydnære LIA-transkripsjonen..
Over søkjeresultata til høgre kan du sjå kor mange treff du får. Det blir presentert 50 søkjeresultat per side. Er det fleire, blir dei presenterte over fleire sider som ein kan klikke seg inn på.
Over søkjeresultata finn du knappar for nedlasting og sortering, sjå 1.7. og 1.8. Søkjeresultatvisninga Concordance er den førehandsvalte visninga, men du kan òg få ulike statistiske visningar av søkjeresultatet, sjå 1.5. for geografisk kart eller 1.6 for statistikk.
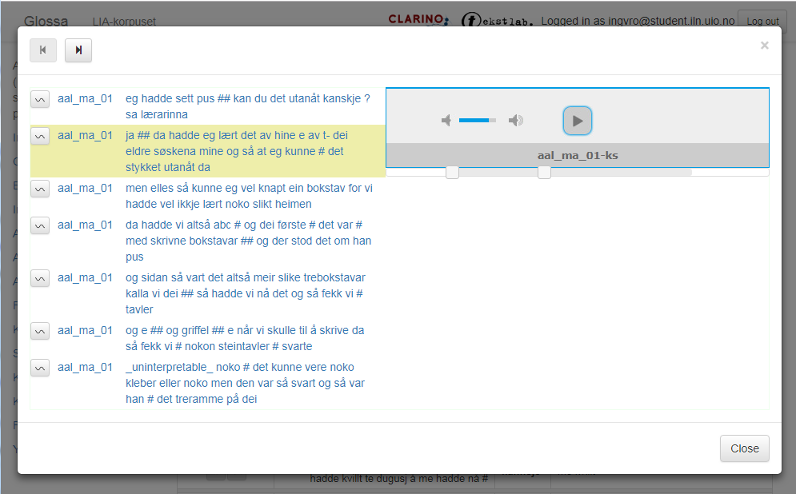
Dersom du held musepeikaren over ordet, får du opp eit lite vindauge med informasjon om lemma, ordklasse, annan morfologisk informasjon og taggar, sjå figur 3. Les meir om ordklasser og taggar i 1.2.2.3 og 1.2.2.4.
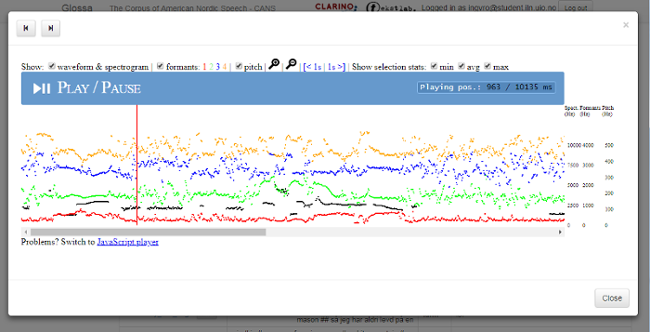
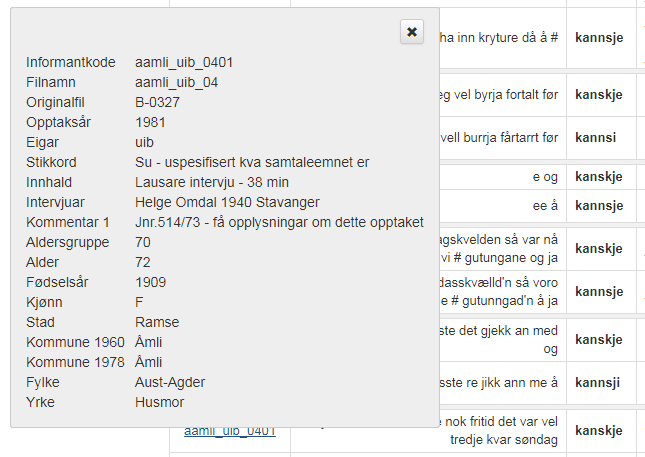
Til venstre for søkjeresultata er det tre ikon/knappar. Klikk på Trans-knappen og få ei engelsk oversetting av resultatet frå Google Translate. Klikk på lydikonet for å få opp lyd (sjå figur 4). I avspelingsboksen kan ein få meir kontekst ved å dra firkantane under boksen til venstre og/eller høgre. Klikk på det tredje ikonet for å få opp lydbølgje og spektrogram for søkjeresultatet (sjå figur 5). Klikk på informantnummeret for å få opp metadata om informanten (sjå figur 6).
Figur 2: Søkjeresultat for enkeltord i korpuset.
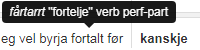
Figur 3: Dersom du held musepeikaren over eit ord i søkjeresultatet, får du opp eit lite vindauge med informasjon om lemma, ordklasse, anna morfologisk informasjon og taggar. I LIA norsk ser du òg den lydnære transkripsjonen.
Figur 4: Lydavspeling av søkjeresultatet.
Figur 5: Lydbølgje og spektrogram.
Figur 6: Metadata om informanten.
1.2.2 Utvida søk (Extended)
Utvida søk (sjå figur 7) gir fleire søkjemoglegheiter. Du kan søkje både på enkeltord og fraser, på lemma, starten eller slutten på ord, på lydnær stavemåte eller på starten eller slutten på segment. Vel du Phonetic form, vil du berre få resultat frå den lydnære transkripsjonen. Du kan òg søkje på ordklasser, morfologiske trekk eller andre taggar.
1.2.2.1 Søk på fleire ord
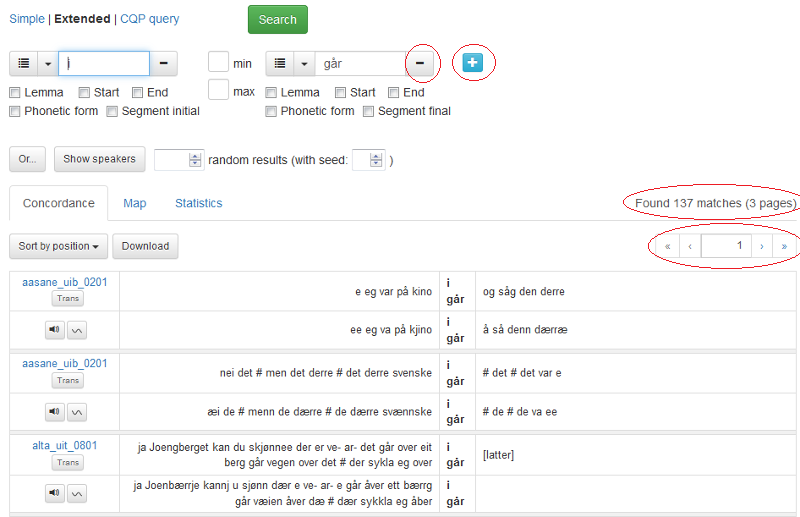
Dersom du fyller inn noko i den første søkjeboksen og klikkar på det blå plussteiknet til høgre, får du opp ein søkjeboks til. Du kan lage så mange søkjeboksar du vil. Mellom søkjeboksane kan du definere kor mange ord det minimum eller maksimum skal vere mellom søkjeorda. Du fjernar ein søkjeboks ved å klikke på minusteiknet til høgre i boksen.
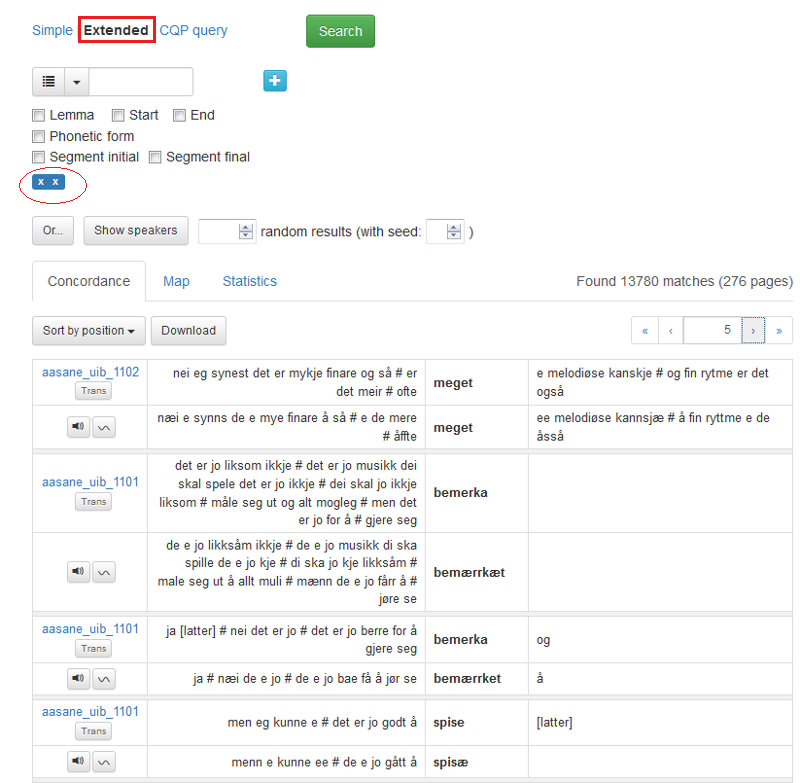
I figur 8 er det blitt gjort eit søk på frasen i går. Det er funne 137 resultat som blir presenterte over 3 sider. Klikk på pilene for å navigere i søkjeresultata.
Figur 8: Søk på fleire ord.
1.2.2.2 Søk på Lemma, Start, End, Segment initial, Segment final eller Phonetic form
Under søkjevindauget er det fem boksar der ein kan krysse av for Lemma, Start, End, Segment initial, Segment final eller Phonetic form. Dersom du kryssar av for Lemma, får du treff på alle bøyingsformene av eit ord. For søkjeordet bok får du både bok, boka, bøker og bøkene som resultat dersom orda finst i korpuset.
Kryssar du av for Start eller End, får du alle orda som startar med ordet eller bokstavane som står i søkjeboksen. Eit søk på bok der Start er kryssa av, kan gi resultat som bokmål eller bokstavar. Er End kryssa av, kan resultata vere ord som lesebok eller framandordbok.
Når du skriv eit ord inn i søkjefeltet, vil du søkje i den ortografiske delen av korpuset. Eit kryss i Phonetic form gjer at du søkjer i den lydnære delen av korpuset. I figur 2 er kanskje uttalt kannsi. Søkjer du på kannsi og krysser av i Phonetic form, får du 24 treff. Du kan søkje i lydnær og ortografisk versjon samtidig. Les meir om dette i 1.2.2.5.
Transkripsjonane i LIA norsk består av segment og ikkje setningar i skriftspråkleg forstand. Segmenta er skilte frå kvarandre, ikkje med punktum, men med tidskodar som seier kvar i videoen eller lydfila segmentet startar eller stoppar. Segmenta vil ofte svare til skriftspråklege setningar, men sidan dette er talemål, kan det òg vere snakk om ufullstendige setningar utan subjekt og finitte verbal.
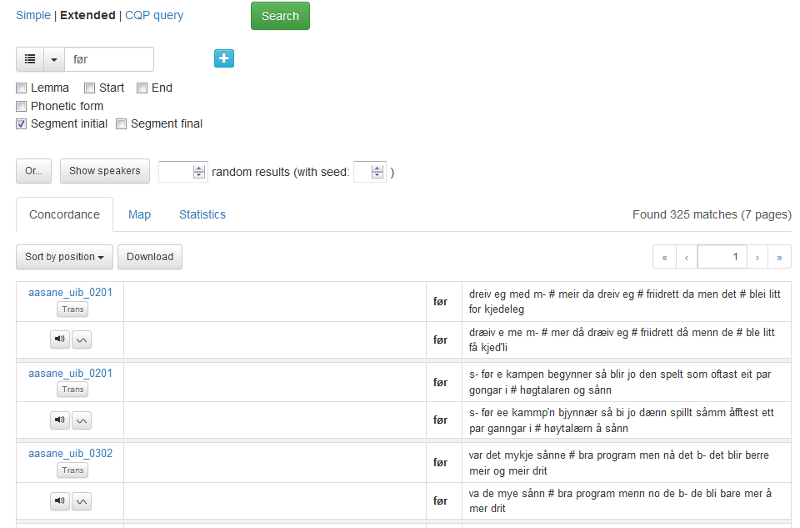
Kryssar du av for Segment initial, spesifiserer du at søkjeuttrykket skal komme først i eit segment. Eit kryss i Segment final tyder søk på det siste ordet. Figur 9 viser eit søk på ordet før i Segment initial.
Figur 9: Før i Segment initial-posisjon.
1.2.2.3 Søk på ordklasse eller morfologiske trekk
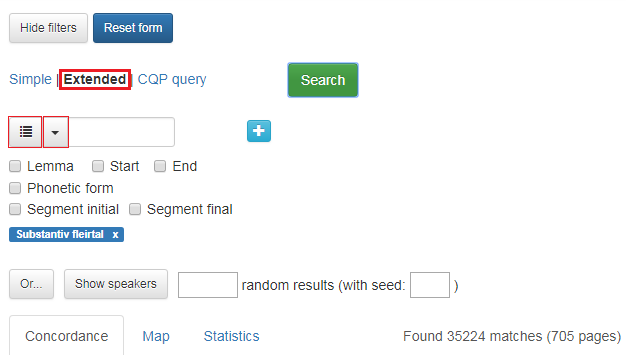
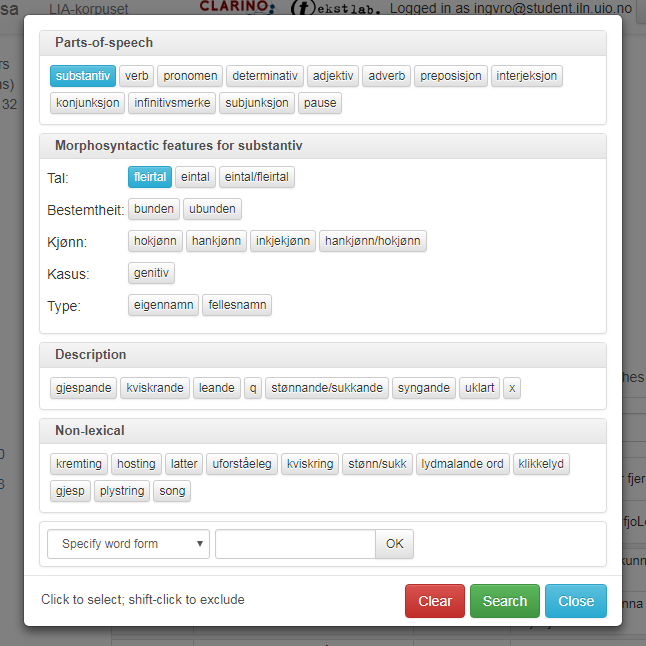
I utvida søk kan du søkje på ordklasse ved å bruke nedtrekksmenyen som skjuler seg bak pila til venstre i søkjeboksen, sjå figur 10. Klikkar du på knappen til venstre for pila, får du opp boksen i figur 11. Vel du ein ordklasse under Parts-of-speech, får du òg tilgang til vala under Morphosyntactic features for den ordklassen du har valt. Vala dine kjem opp i små, blå boksar under søkjefeltet. I figur 10 er det søkt på Substantiv fleirtall.
Dei andre avkryssingsmoglegheitene i boksen på figur 11 blir forklart i kapitla under.
Figur 10: Knappane for ordklassesøk og søk etter andre morfologiske trekk.
Figur 11: Søk på ordklasse og annan morfologisk informasjon.
Viss du klikkar på fleire ordklassar samtidig, for eksempel både substantiv og pronomen, vil du få treff på alle orda som er anten substantiv eller pronomen.Tilsvarande kan du klikke på fleire verdiar innanfor ein kategori, for eksempel både hokjønn og hankjønn i kjønn-kategorien under substantiv, for å få treff på substantiv som er anten hokjønn, hankjønn eller begge delar.
1.2.2.4 Søk på andre taggar (latter, ord som ikkje står i ordboka osv.)
Under skildring og ikkje-leksikalsk i søkjeboksen skildra i 1.2.2.3 ovanfor (figur 11), kan du søkje på taggar som anten skildrar orda eller som er sjølvstendige hendingar i talestraumen:
Skildring:
X: Opptaka er transkriberte ortografisk med Nynorskordboka (2012) som rettesnor. Ord som ikkje står i ordboka, blir merka med taggen x. I LIA norsk er dette som regel dialektord eller ord frå andre språk. Merk at samansetningar med etterledd som står i ordboka, ikkje blir merka som x.
Q: Ord i hermeteikn ("quoted"), som sitat og namn på filmar, bøker og leker osv. Eitt eller fleire ord.
Uklart: Ord som transkribøren er usikker på.
Leande: Ord som blir sagt mens informanten ler.
Kviskrande/syngjande/gjespande: Ord som blir kviskra, sunge eller blir sagt mens informanten gjespar.
Stønnande/sukkande: Ord som blir sagt mens informanten sukkar eller stønnar.
Kryssar du av for ein eller fleire av taggane ovanfor, får du treff på orda som er knytta opp til dei.
Ikkje-leksikalsk:
I denne kategorien finn vi kremting, hosting, latter, uforståeleg, kviskring, stønn/sukk, lydmalande ord, klikkelyder, gjesp, plystring og song. Dette er altså sjølvstendige hendingar i talestraumen.
Uforståeleg: eit eller fleire ord som er så utydelige at dei ikkje kan transkriberast.
Kryssar du av for ein eller fleire av taggane ovanfor, får du treff på hendinga - for eksempel latter.
I figur 12 er det søkt etter ord som er merkte med x-taggen. Det kan vere nyttig å høyre lyden for å få oversikt over segmentet og konteksten rundt.
Figur 12: Søk på ord som er merka med x.
1.2.2.5 Spesifiser eller ekskluder lemma og ordform
Nedst i
den morfologiske søkjeboksen i figur 10 er det eit felt der du ytterlegare kan spesifisere eit søk. Vel du for eksempel verb i den morfologiske søkjeboksen, men berre er ute etter hjelpeverba, kan du velje Specify lemma og leggje til hjelpeverba eitt for eitt i boksen til høgre og trykke OK mellom kvar gong.
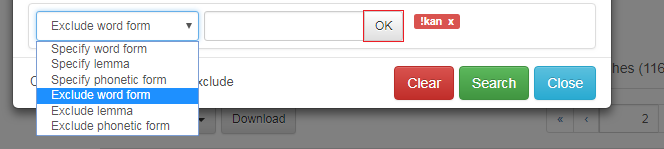
Dersom du har valt verb, men ikkje vil ha med hjelpeverba, gjer du det på same måte, men vel Exclude word form eller lemma.
Har du valt å søkje etter Phonetic form, som blei skildra i 1.2.2.2, kan du spesifisere kva for ortografisk ordform eller lemma ordet skal ha i Specify word form eller lemma. Søk for eksempel på Phonetic form og je og Specify word form, eg, og du får alle tilfella der eg blir uttala je.
NB! Hugs å klikke på OK når du har skrive inn eit ord i boksen! Ord som er ekskluderte, vil da kome opp på høgre side i raudt med eit utropsteikn foran, sjå figur 13 og figur 15. Ord som er spesifiserte, kjem opp i blått.
Figur 13: Spesifiser eller ekskluder lemma og ordform.
1.2.3 CQP-søkjeuttrykk (CQP query)
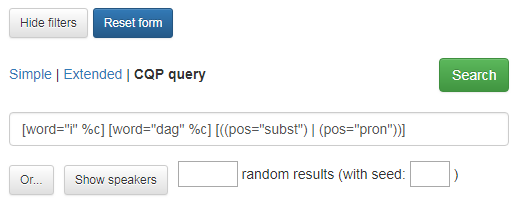
CQP-søkjeuttrykk kan brukast til avanserte søk som ikkje er moglege i enkelt søk eller utvida søk. For å bruke denne moglegheita må du kunne CQP-søkjespråket. Om du treng hjelp til eit avansert søk, kan du ta kontakt med Tekstlaboratoriet. Figur 14 viser eit eksempel på korleis søk etter orda i dag etterfølgt av substantiv eller pronomen ser ut i anten utvida søk (Extended) eller i CQP query. Dersom du har brukt moglegheitene i Extended search og lurer på korleis dette søket ser ut på CQP-søkjespråket, klikkar du på CQP query, så får du opp søkjeuttrykket som i figur 14.
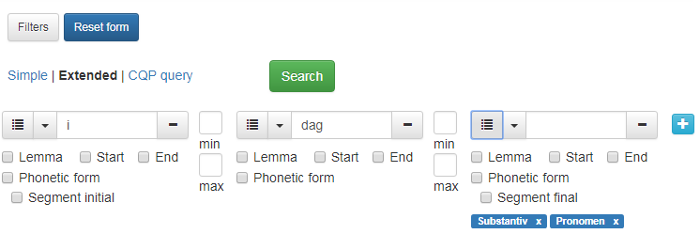
Figur 14: Eksempel på same søk i Extended og CQP query.
1.2.4 Eller-søk (Or)
Ved å klikke på Or-boksen får du opp eit nytt søkjevindauge under det andre. Søk i denne boksen gir eit eller-søk. Det vil si at du søkjer på ordet i hovudsøkjeboksen eller ordet i Or-boksen. Du kan lage så mange Or-boksar du vil, og du slettar dei ved å klikke på det raude krysset til venstre for boksen.
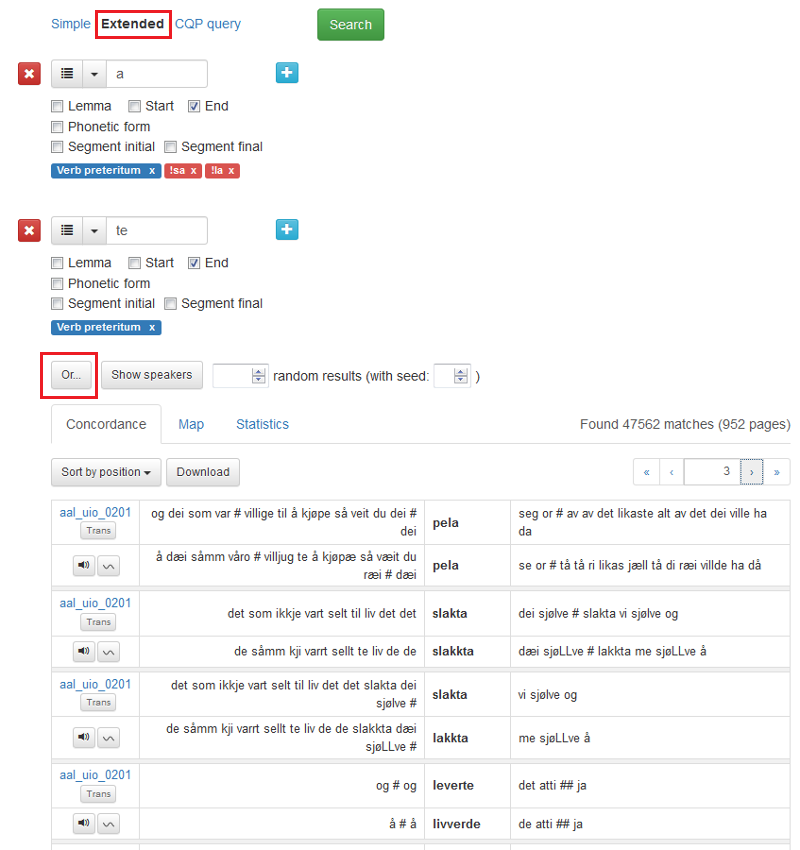
Figur 15 viser eit komplisert søk etter verb i preteritum som endar på anten -a eller -te. Verba sa og la er ekskluderte.
Figur 15: Or-søk.
1.3 Metadatasøk og Show speakers
Til venstre i søkjeskjemaet er alle metadatakategoriane ramsa opp. For LIA norsk er kategoriane: Informantkode, Kjønn, Kommune 1960, Kommune 1978, Fylke, Eigar, Opptaksår, Aldersgruppe, Alder, Fødselsår, Stad, Yrke.
NB! Sidan LIA norsk er eit korpus med eldre dialektopptak, har det ikkje vore mogleg å samle fullstendige metadata for alle informantane. Dei seks øvste kategoriane skal vere utfylte for alle: Informantkode, Kjønn, Kommune 1960, Kommune 1978, Fylke og Eigar. Dei andre kategoriane er utfylte der det er funne informasjon. Dette betyr til dømes at om du vel 72 år i alderskategorien, vil du få søkjeresultat frå alle som er registrerte i metadata-basen som 72 år, ikkje frå alle dei eventuelle 72-åringane i korpuset vi ikkje kjenner alderen til.
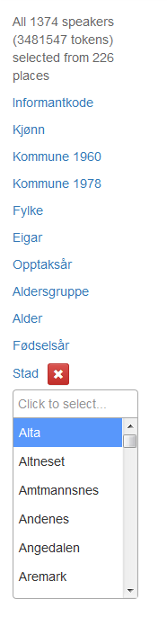
Klikkar du på ei av lenkene i metadatamenyen, kjem dei ulike verdiane i kvar kategori opp. Du kan klikke på og velje ein eller fleire, og valet du gjer, blir synleg i ein boks under kategorien. Klikkar du på det raude krysset, blir valet nullstilt. Figur 16 viser korleis metadatamenyen ser ut når ein har klikka på kategorien Stad.
Figur 16: Metadatamenyen når det er klikka på Stad.
Valet du gjer, avgrensar dei vidare moglegheitene du har for søk. Har du valt for eksempel F i kategorien Kjønn, vil du berre kunne velje verdiar som er knytt til dei kvinnelege informantane. For eksempel vil du ikkje få valet Amtmannsnes under Stad. I figur 17 er det berre kryssa av for Aremark under Stad.
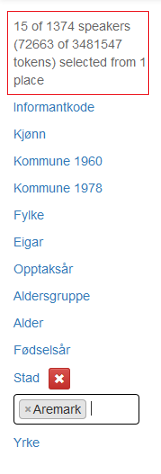
Figur 17: Aremark er valt under Stad.
Over metadatakategorimenyen er det ein teljar som til kvar tid viser deg kor mange informantar du har valt og kor mange tokens utvalet da består av. I denne versjonen inneheld LIA norsk 1374 informantar og 3 481 547 tokens (ord og skilleteikn) slik figurane ovanfor viser. Når det er valt berre informantar som er frå Aremark, avgrensar utvalet seg til 15 informantar og 72 663 tokens slik figur 17 viser.
Dersom du ønskjer å sjå ei samla oversikt over informantane du har valt, klikkar du på Show speakers-knappen nedanfor ordsøkjeboksen ved siden av Or-knappen, sjå figur 15. Resultatet blir som i figur 18 for utvalet frå figur 17. (NB! Vi jobbar med ein penare presentasjon som er lettare å lese. Bildet nedafor er kraftig forminska for å vise at ein kan sjå mange kateforiar metadata til høgre ved å bruke linja nedst i vindauget.
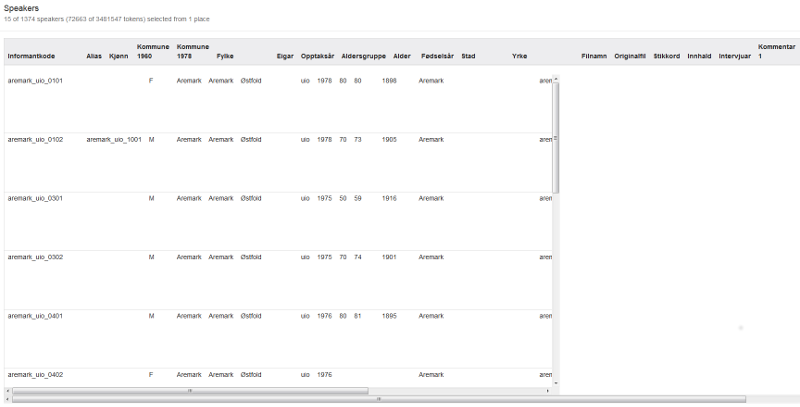
Figur 18: Show speakers-vindauget.
Dei ulike metadatakategoriane frå Show speakers-vinduet er kort skildra nedanfor. Ver merksam på at berre kategoriar med stjerne framfor i oppramsinga, har metadata for alle informantar.
* Informantkode: Kvar informant har fått tildelt ein kode i staden for namnet sitt. Informantkoden består av stadnamn, forkorting for universitetet som eig opptaket, nummer på lydfila og to siffer som representerer informanten. Viss desse to siffera er høgare enn 01, indikerer det at det er fleire enn ein informant i det opptaket, sjå til dømes figur 18.
Nokre informantnummer ser annleis ut, sjå til dømes figur 2. Her består informantkoden av stadnamn, forkortinga ma og to siffer som representerer informanten. Desse opptaka stammar frå Nordisk dialektkorpus der det vart transkribert filer frå Målførearkivet ved Universitetet i Oslo. Transkripsjonane er flytta til LIA norsk og translittererte til nynorsk. (Dei norske transkripsjonane i Nordisk dialektkorpus blei transkriberte til bokmål).
Du kan søkje på ein eller fleire informantkodar.
Alias: Viss informanten er med på to eller fleire opptak, kan du sjå dette ved å velje ein informantkode og sjå om eitt eller fleire alias dukkar opp.
* Kjønn: blir vist som M eller F.
* Kommune 1960: Informanten sin heimekommune etter inndelinga frå 1960. Dette er stadnamnet i informantkoden og staden som blir vist på kartet, sjå figur 20.
* Kommune 1978: Informanten sin heimekommune etter inndelinga frå 1978.
* Fylke: Fylket informanten kjem frå.
* Eigar: Kva for eit universitet som eig opptaket.
Opptaksår: Årsstalet opptaket blei spelt inn.
Aldersgruppe: Aldersgruppa er delt inn i tiår og viser kva for tiår informanten tilhøyrer.
Alder og Fødselsår: Alder og fødselsår til informanten.
Stad: Staden informanten kjem frå.
Yrke: Kva for eit yrke informanten har.
Filnamn: Fornamnet transkripsjonsfila har fått i LIA-prosjektet.
Originalfil: Namnet på originalfila (namn gitt av universitetet som eig fila).
Stikkord: Stikkord eller kode for innhaldet i fila.
Innhald: Innhaldet i fila.
Intervjuar: Namn på intervjuar(ane). Er nokre gonger med årstal.
Kommentar 1: Kommentar til lydfila eller transkripsjonen.
Kommentar 2: Kommentar til informanten.
1.4 Tilfeldig utval av søkjeresultata
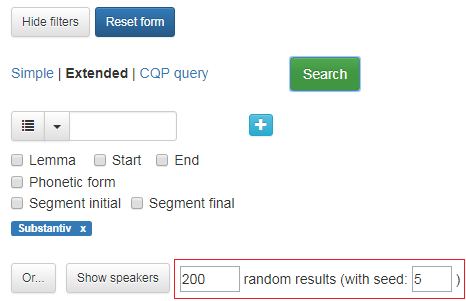
Dersom ein har eit søk som vil gi mange treff, kan ein velje å få sjå berre ei viss mengd tilfeldig utvalde treff. Spesifiser mengda treff i boksen ved sidan av Show speakers-knappen.
Dersom du vil skape akkurat dette resultatet igjen seinare, vel du eit tall og set det inn i boksen with seed. I figur 19 er det søkt etter alle substantiv i korpuset, med ei visning på 200 tilfeldig utvalde treff. Talet 5 er skriven i with seed-boksen. Kvar gang du gjer det same søket og skriv det same talet i boksen, får du det same tilfeldige utvalet av søkjeresultata. Skriv du eit anna tal, får du eit anna tilfeldig utval.
Det er mogleg å velje eit tilfeldig utval av søkjeresultata for søk som er Extended eller CQP query.
Figur 19: Avkrysningsboks for å få eit tilfeldig utvalg av søkjeresultata, her med 200 tilfeldige resultat.
1.5 Kart
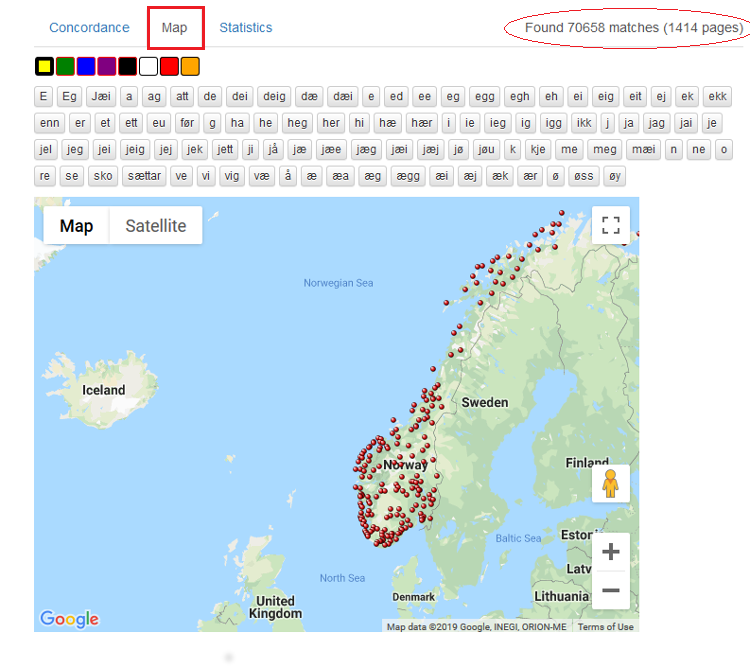
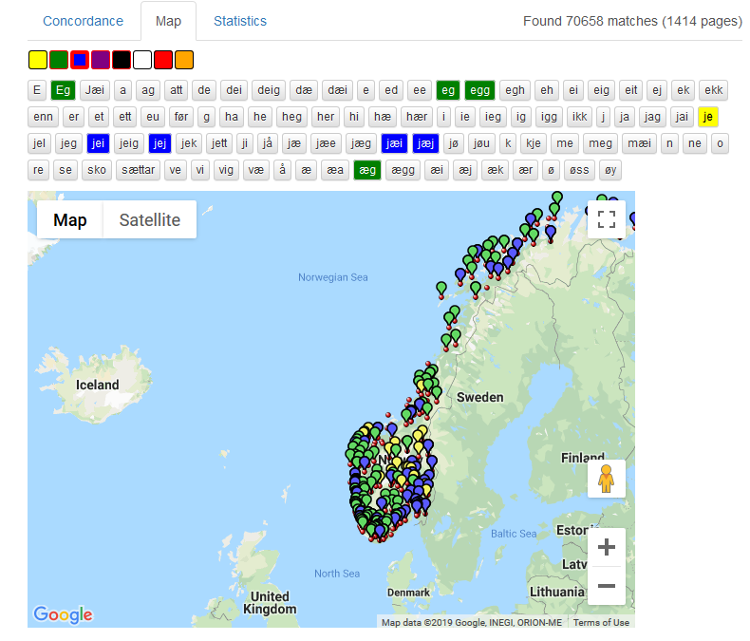
Søkjeresultatvisninga Concordance er den som er førehandsvalt og som alle eksempla ovanfor er henta frå. Vel du Map som er vist i figur 20 nedanfor, kan du få ei kartleg oversikt over utbreiinga av eit ord og dei ulike variantane av ordet som finst i korpuset. Du kan zoome inn og ut på kartet for å få ei betre oversikt.
I figur 20 har det blitt gjort eit søk etter ordet eg. Dei raude prikkane på kartet markerer kvar informantane som har brukt ordet, kjem frå.
Figur 20: Kart som viser variantar av eit søkjeord og kvar dei er brukte.
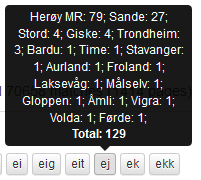
Ved å halde musepeikaren over ein variant, som i figur 21, får du opp eit vindauge med informasjon om kva stader varianten er brukt, kor mange gonger han er brukt på kvar stad, og kor mange treff det er for varianten totalt. Tal på treff for alle variantane samanlagt finn du i høgre hjørne over kartet, sjå figur 20.
Figur 21: Viser fordelinga av variantane til eit ord og kor mange som er registrerte på kvar stad.
Ved å klikke på ein farge og deretter på ein variant, kan du sjå utbreiinga av varianten på kartet. I figur 22 under er nokre av variantane markerte med fargane gul, grøn og blå. For å fjerne fargen klikkar du ein eller to gonger på boksen inntil fargen på boksen blir grå igjen.
Figur 22: Du kan bruke fargane for å sjå utbreiinga av variantane.
1.6 Statistikk
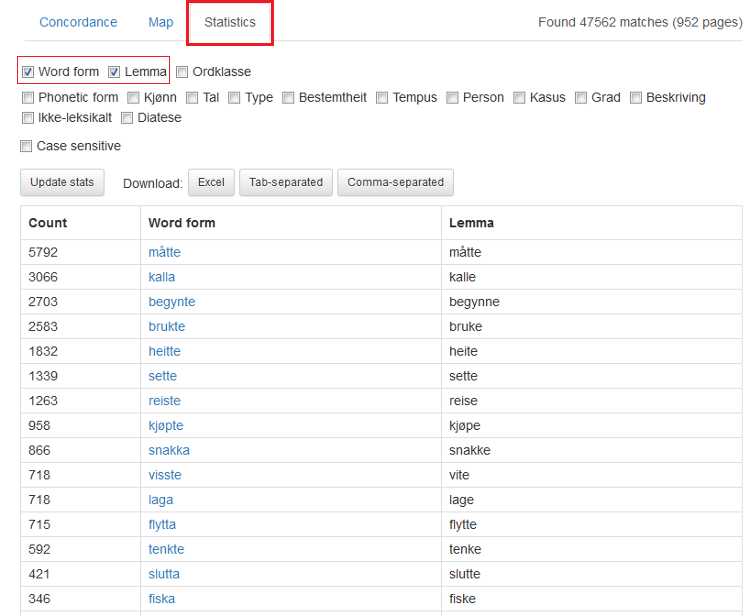
Søkjeresultatvisninga Concordance er førehandsvald og er den som alle eksempla ovanfor er henta frå. Vel du Statistics som i figur 23 nedanfor, kan du be om ulike frekvensteljingar og statistikk. Foreløpig er det boksane over Update stats som kan veljast. Kryss av for kva du vil sjå, og trykk Update stats. Eksempel 20 viser frekvensar frå søket i figur 15, altså søk etter verb i preteritum som endar på anten -a eller -te. Verba sa og la er ekskludert. Frekvensane er til venstre og ordforma til høgre.
Figur 23: Statistikkvisning for søkjeresultatet frå figur 15.
1.7 Last ned data
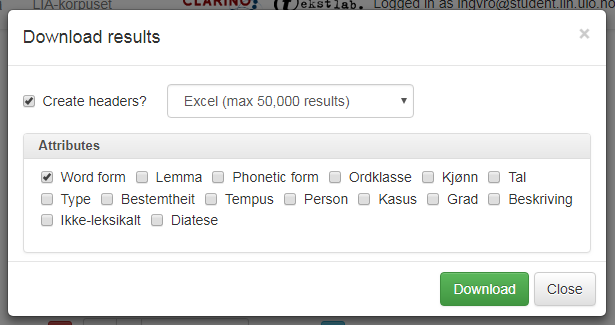
Klikkar du på Download-knappen over søkjeresultata (sjå figur 2), får du opp ein dialogboks der du kan velje fleire nedlastingsformat: Excel-fil, tabseparert tekstfil eller kommaseparert tekstfil. Du kan òg velje kva for informasjon som skal lastast ned, sjå figur 24.
Figur 24: Vindauget for nedlastingsalternativ.
1.8 Sorter søkjeresultata
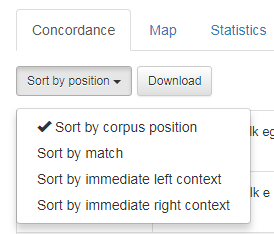
Søkjeresultata kan sorterast på ulike måter slik figur 25 viser: Dersom du vil sortere etter søkjeordet, vel du Sort by match. Du kan òg sortere etter ordet rett til venstre eller ordet rett til høgre. Legg merke til at skiljeteikn blir alfabetisert før a og b osv.
Figur 25: Søkjeresultata kan sorterast på ulike måtar.