
Example
Searches
On this page a few example searches will be
presented, along with a quick intro to dealing with search results. The
examples are meant to illustrate some basic
functions of the
Glossa interface. A more thorough
walk-through of all
of the functions the interface has to offer is found in The full User
Manual. See also The Search Interface Documentation.
Contents
Example
1 - Searching for a Specific Word Form in
a Specific Language
Example 2 - Searching for Phrases, Lemmas and Classes of Words Defined
by Grammatical Criteria
Example
3 - Searching for Compounds Using Parts of Words
Example 4 - Searching for Semi-Phonetic Alternants of
Specific Words
A Quick
Intro to Dealing with Search Results
Example 1 - Searching
for a Specific Word Form
in a Specific Language
The
first example will show
how to search
for a
specific word form in a specific language.
To illustrate, we are going
to look at a word that varies a lot across different Norwegian
dialects, namely the first person pronoun "jeg".
To start out, we'll need to type the word into the word box in the
linguistic search field (top red box, figure
1 below).
There are also a couple
of more
advanced
functions that need to be
given
attention, and that are worth keeping in mind for
all searches.
First of all, the maximum number of hits
is limited to 2 000
by default. When searching for very frequent
words (like e.g.
"jeg") this number might be to small to include all occurrences in the
corpus. If it is of interest to include all occurrences, this number
should therefore be adjusted up. In this example we'll set the number
to 200 000 (middle red box, figure 1 below).
Second, a search in the corpus will by default include
dialects from all
languages
represented, i.e.
Danish, Faroese, Icelandic, Norwegian and Swedish. In other words, if
the query matches a word in the standard orthography of any
one
of these languages that is actually found in the
corpus, it will be included in the search results. The first person
pronoun is written "jeg" not only in Norwegian, but also in Danish (and
partially in the Faroese transcriptions). The query "jeg"
will therefore give "unwanted" Danish and
Faroese hits in addition to the Norwegian hits we are interested in for
this example.
For this (and the following)
example searches, we are therefore going to limit
the search to
Norwegian
dialects only. This is done
by
expanding the
country table (bottom red box,
figure 1), and
then double-clicking Norway. Norway will then move from the left
column (excluded) to the right column (included). To deselect Norway,
double click it again.
Using the Metadata Specification Field, it's possible to limit searches
to
geographic areas and specific informants. It's also possible to include
or exclude informant groups based on age group and sex, the year the
recording took place and what genre the recording is (interview or
conversation). If you want to check which informants that are going to
be included in the search based on your current selections in the
Metadata Search Field, you can press the show informants button on the
right hand side. A new window will then open showing you a table of the
included informants with available metadata. More information on data
collection is available here.
When
all the variables are entered, your
interface will look like the one showed figure 1 below. You are then
ready to
press the search
corpus button. A new
window will then appear with the search results. A brief guideline on
how to handle search results is found below.
This
search will only give hits where the
transcription includes the
specific word form "jeg". In other words, the oblique
form "meg" will not be included among the hits. In Example
2, you will see how to search
for
lemmas and classes of words defined by grammatical criteria.
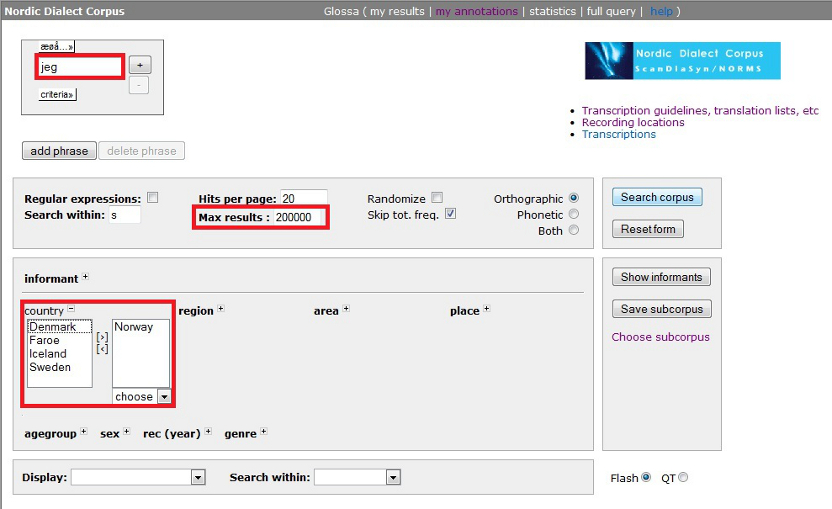
Figure 1 - Glossa search interface ready for
example search 1
Back to top.
Example
2 - Searching for Phrases, Lemmas and Classes of Words Defined by
Grammatical Criteria
This
example will show how we can search for phrases, lemmas and grammatical
categories. We will illustrate this by looking at Norwegian
collocations consisting of a verb followed by
the negative adverb "ikke". In such collocations we often
find
phonetic/phonological alternations of either or both words.
In order to add
an extra word box to
the search, thus making it a
search
for
a multi-word phrase instead of a search for a single word, click the
plus-button (+) on the right side of the word box. You are now
presented
with two such boxes instead of one. The extra word box may be
removed again by clicking the minus-button (-).
Now for this example,
the first
word of the phrase
should be a verb. Since the transcriptions are morphologically tagged,
it is possible to search for a class
of words defined by grammatical
criteria. These criteria are
found in
the expanding menu directly below
the word box. For this example, we find the verb criterion under pos
("part of speech"). Click it, and it will show up
in a
new white box below the word box, cf. figure 2 below. Selected
criteria may be removed again by double clicking them.
The tagging
process itself has been done automatically, which gives some
shortcomings. For example, the corpus
unfortunately includes some words that are incorrectly tagged.
It's therefore important to remember that
searching for specific word forms always will retrieve the hits you
expect,
while that is not necessarily the case when the search includes classes
of words defined by grammatical criteria. For a discussion on this, and
an overview of the searchable criteria, cf. the full user manual
(coming soon).
Continuing
with the example search, we'll simply enter "ikke"
in the second word box. This gives us a query
consisting of a two word collocation where the first word is defined as
belonging to the grammatical category verb and
the second word is "ikke".
Now,
say we were only interested in looking
at alternations in collocations where the verb is in the present tense.
This can easily be done by adding
another
criterion,
namely pres
("present") that we find under temp
("tempus"/"tense").
If we now set the max results number to 200 000 and narrow the
search
only to
include Norwegian dialects like we did in example
1 above, we are
ready to press the search corpus button. A new window will appear with
the search results (more about handling results below).
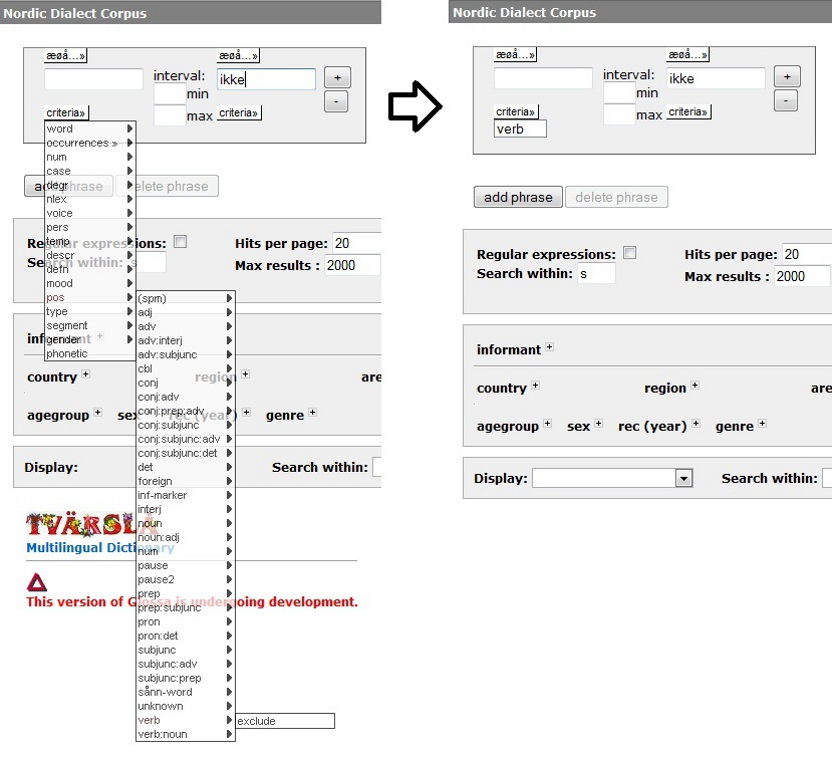
Figure 2 - Selecting criteria: pos
("part of
speech")
- verb
Let's say that through the search above, we find particularly
interesting alternations in collocations containing different forms of
one specific verb, e.g. "skulle"
("should"). We therefore want to study all collocations with all forms
of this particular verb more thoroughly. In order to do this, we can perform
a lemma search. This is also
done using the criteria menu.
First of all, we need to enter the dictionary form of the verb into the
first word box. Then we find and click
the lemma criterion
under word
in the
criteria menu, cf. figure 3. It will pop up in a new white
field under the search field itself, in the same way as the criteria
verb
and pres
described above (to remove the other criteria, simply double click
them). We are now ready to perform a new search with a query consisting
of the lemma "skulle",
giving us all forms
of this verb, followed by the word form "ikke".
Note that only Norwegian and Danish transcriptions are lemmatized for
now, so using lemma based queries in any of the other languages
unfortunately won't work.

Figure 3 - Selecting criteria: word
-
lemma
Back to top.
Example 3 - Searching
for
Compounds Using Parts of Words
A practical way to search for compounds is using the different parts of
words criteria. For this example, let's say we're interested in finding
Norwegian compounds in which one of the elements is "gutt" ("boy"). In
compounds with two elements, "gutt" may then be initial or
final, and if we find compounds with more than two elements, it may
even be medial.
First, we'll see how we can find compounds where "gutt" is the initial
element. We start out by entering gutt into the word box in the
linguistic search field (cf. example 1).
Then we open the criteria menu and select word, then start of word. We
now have a query that will retrieve
all words starting with "gutt", as
well as all forms of the word "gutt" itself. Since we are
interested only in compounds, we want to filter out the occurrences of
the lemma "gutt" (i.e. the word forms
"gutt, gutten, gutter, guttene"). Since the Norwegian
transcriptions are lemmatized, this is easily done by excluding the
lemma "gutt" from the query using the add negated lemma criterion (also
under word). The linguistic search field will now look like the one in
figure 4a below. If we were searching for compounds in one of the
languages that aren't lemmatized, we would have to exclude every
possible word form of the lemma in question using the add negated word
form criterion to achieve the same result.
The same method can be used to find compounds where "gutt" is the
medial or final element, but here we need to perform two searches to be
sure that we find all possible hits. First, to find compounds where
"gutt" is the final element (in its indefinite singular form), we
simply perform a search identical to the one described over, only using
the end of word criterion instead of the start of word criterion. For
this search, the linguistic search field will look like the one in
figure 4b below. Second, to find compounds where "gutt" in a medial
element, or compounds where "gutt" is final and in any other form than
the indefinite singular ("-gutten, -gutter, -guttene"), we can drop
using the add negated
lemma criterion and only make use of the within word criterion. For
this search, the linguistic search field will look like the one in
figure 4c below.
Knowing some basic regular expressions gives you a lot more flexibility
when searching for parts of words. You can read more about regular
expressions in the full user manual (coming)
.
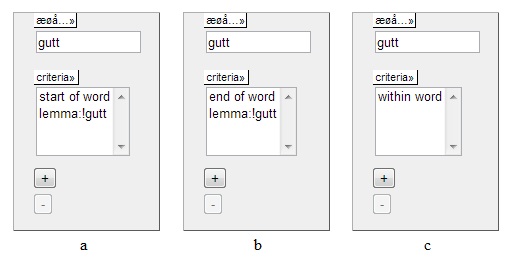
Figure
4 - Searching for compounds where one of the elements is "gutt"
Back to top.
Example 4 - Searching
for
Semi-Phonetic Alternants of Specific Words
In example 1,
we used the orthographic word form of the Norwegian first person
pronoun
"jeg" to search for phonetic variation in Norwegian
dialects. In this example,
we'll see that it's also possible to go the other way around. We can in
other words search for known semi-phonetic alternants of words to find
out how frequent they are or what their geographical distribution might
be. This is only possible for Norwegian dialects, since these are the
only that are transcribed both orthographically and
semi-phonetically. Read more about the transcription of the Norwegian
recordings here,
and read the transcription guidelines here (especially section 3.4, Norwegian only).
For this example, we're interested in finding the distribution for a
typical South Eastern Norwegian variant of the negative adverb "ikke".
The form may vary in the semi-phonetic transcription, depending on
vowel quality and whether we have the full form or the clitic, but
common to all these forms is that they end in "nte".
In order to perform this search
then, we need to enter the query "nte"
into the word box in the
linguistic search field, just like we would have if we were searching
for
an orthographic word form. But now we also have to specify
that the search is
to be performed in the semi-phonetic transcriptions.
To do this, we have to select
the phonetic
criterion from the criteria menu. We also need to select the the end
of word
criterion that we find in the word
subsection of the criteria menu in order to specify that our query
consists of an ending common to several possible word forms.
Finally, we want to specify that what we're looking for is alternants
of the orthographic word form "ikke". This is done by entering
"ikke"
in the pop-up window that appears when we select the criterion
word
- add
word form. If we drop this
last step, our query will return
hits of all words ending in "nte" in the semi-phonetic transcription.
In figure 5 below, we see the linguistic search field prepared for this
example search. Note that it's also possible to combine the phonetic
criterion with other
criteria, like e.g. parts of speech.
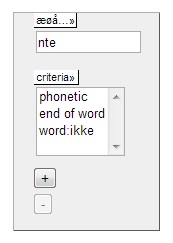
Figure
5 - Searching part of a phonetic alternant of a specific word
form
Back to top.
A Quick Intro to
Dealing with
Search Results
The search results will always open in a new window like the one showed
Figure 6 below. Here we've searched for "jeg", the first
person pronoun in Norwegian dialects, like in example
1 above. For this section
though, the
maximum number of
hits is set to 200 and the hits are randomized.
At the top of the page, you'll find the total number of informants
included in the search (505). A bit further down, you'll see the number
of hits available to you and how many hits there are in total (200 and
52 630).
The hits are presented 20 per page by default, but this is
adjustable (cf. the full user manual - coming soon). Each hit is
presented in the form of a segment containing the
word (or
phrase) searched for, which in
turn
is bolded out. The code of the informant having uttered the segment is
in the left column, and here you also find three clickable buttons. The
first one ( ) opens information
about the informant
in a new window. The two following buttons (
) opens information
about the informant
in a new window. The two following buttons ( and
and  ) open
video and audio or just audio
for the current segment on top of the results page. As is shown in
Figure 6, not all recordings include video, and in such cases there
will just be
an audio button available. The media
player that opens when
clicking the
either of these buttons, is shown in figure 7. By default this
is a Flash player, but if there are problems using Flash, a QuickTime
player may also be used. The segment currently playing is
highlighted
in orange on the right hand side. It is possible to get a wider
context to the right and/or to the left by using the sliders directly
above the play button. In Figure 7, the left context has been adjusted
to include the three preceding segments.
) open
video and audio or just audio
for the current segment on top of the results page. As is shown in
Figure 6, not all recordings include video, and in such cases there
will just be
an audio button available. The media
player that opens when
clicking the
either of these buttons, is shown in figure 7. By default this
is a Flash player, but if there are problems using Flash, a QuickTime
player may also be used. The segment currently playing is
highlighted
in orange on the right hand side. It is possible to get a wider
context to the right and/or to the left by using the sliders directly
above the play button. In Figure 7, the left context has been adjusted
to include the three preceding segments.
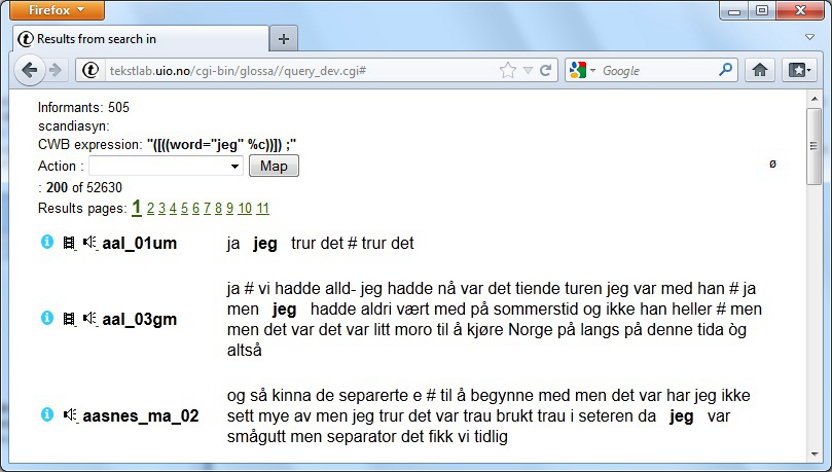
Figure
6 - Search results page
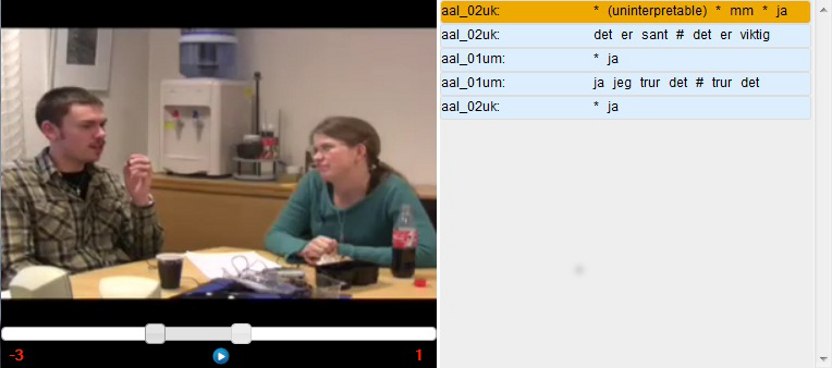
Figure
7 - Media player
There
are several more advanced functions
useful for handling the search results available through the action
drop down menu. Among other things, it's possible to count results,
save results for later reference and export results to various editable
formats. These functions aren't dealt with here, but described in
detail in the full user manual (coming soon). We will, on the other
hand, show
how to use the map function. Basically, this function
shows your hits on a map. When the search is done in Norwegian transcriptions
(that
are transcribed both orthographically and semi-phonetically), you are also shown
phonetic
variation (if you search for a multi-word phrase, phonetic variation is
only shown for the first word). The
goal of example
1 was to find variation in
pronunciation of the first person pronoun in Norwegian dialects. If we
use the 200 hits from the result page shown in Figure 6 above as a
point of departure, we can then click the map button to get a simple
overview shown in Figure 8 below. The recording locations from
which the search
has returned hits are shown as red dots on the map, and the
different
phonetic realizations are shown in a list to the right. By selecting a
color
each phonetic realization may be marked out on the map. To illustrate
this, all
forms that have undergone vowel breaking are marked out with red in the
figure.

Figure
8 - Map over semi-phonetic
"jeg" realizations
Back to top.