
User
Manual
The Nordic Dialect Corpus in the Glossa Interface
By Eirik Olsen
Overview
and Contents
This
user manual is partially based on Lars Nygaard's manual Glossa - The
Corpus Explorer (HTML|PDF).
More about Glossa is also found on its Text
Laboratory site. See also The Search Interface Documentation and The
Example
Searches Page.
The interface
works best with Firefox or Chrome.
1 The Linguistic Search
Field
1.1 The
Criteria Menu
1.1.1 The
Non-Linguistic Criteria
1.1.2 The
Linguistic Criteria
1.2
Searching for (Multiple) Phrases
2 The General
Search Options Field
2.1 Regular Expressions
2.2 Result Options
2.2.1 Hits per
Page, Max
Results, Randomize and Skip
Total Frequency
2.2.2
Orthographic and Phonetic Transcriptions
2.2.3 Changing
Audio/Video Player
2.3 Other Functions
3 The Metadata
Specification Field
3.1 Informant Code Naming Conventions
3.2 The Informant Metadata Categories
3.3 The Recording Metadata Categories
3.4 The Show Informants Function
3.5 The Subcorpus Function
4 Other
Search Interface Functions
4.1 Managing Saved Result Sets
4.2 Managing Annotation
Sets
4.2.1 Creating
and Editing Annotation
Sets
4.2.2
Retrieving Annotation Statistics for Saved Result Sets
4.3 Accessing Complete
Transcriptions in
HTML-format
4.4 Bug and Error Report
5 The
Results Page
5.1 The Media Player
5.2 The Map Function
5.3 The Action Menu
5.3.1
Count
5.3.2
Download
5.3.3 Sort
5.3.4
Collocations
5.3.5
Annotate
5.3.6
Delete Hits
5.3.7
Save Hits
1 The Linguistic Search
Field
The
linguistic search field is shown in figure 1 below. Its most central
part is
the word box, where you
input your query (e.g. a word). This input should normally be
orthographic,
but if the settings are right it may also contain so
called regular
expressions or be semi-phonetic (more about this in 1.1.1 and 2.1).
To
facilitate the insertion of special
characters, you'll find the
characters æ, ø, å, ä,
ö, ð, þ in the
æøå... menu above the word box. You may
also search for classes of
words defined by
linguistic criteria. The criteria menu is explained in detail in
section 1.1 below. Several word boxes may be combined in order to
search for phrases, and also phrases may be combined in the same
search. How to search for (multiple) phrases is explained in section 1.2.
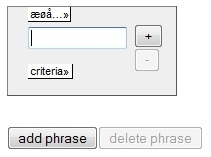
Figure
1 - The linguistic search field
1.1 The
Criteria Menu
The
criteria menu is shown in Figure 1.1a below. You may use criteria to
define
classes of words based on various linguistic and non-linguistic traits.
In the following we will
look closer at some of these criteria, explaining their
function and use. Some examples of criteria used in actual searches are
found on the example
searches page.
In order to select a criterion, simply find it in the drop down menu
and click it. The criterion will show up in a white field below the
criteria menu (cf. Figure 1.1b). Selected criteria may be
removed
again by double clicking them. More
than one criterion will be connected by disjunction, meaning that
you'll get hits on a query matching either criterion (or both).
Most criteria can also be excluded from
a query, in which case they will appear with a prefixed exclamation
mark when you select them. Excluded criteria are also connected to each
other by disjunction,
but are connected to other criteria by conjunction. This means that
words
matching excluded criteria will not be included among the hits even if
they also match non-excluded criteria.
Figure
1.1a - The Criteria Menu
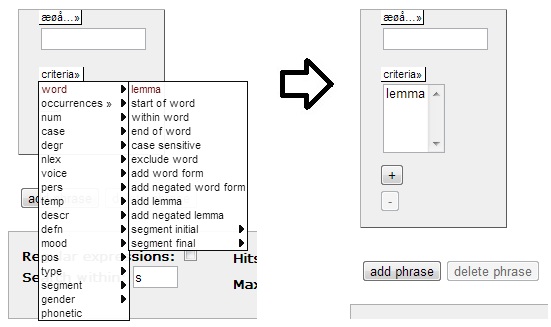
Figure
1.1b
- Selecting a Criterion
The selection of criteria is based on automatic tagging of the
transcriptions of the different languages. There are some
shortcomings of automatic tagging, which means
that some words unfortunately are incorrectly tagged. This may cause
two related problems that it's important to keep in mind when searching
using criteria. First of all, your query may match words that are
incorrectly tagged as the kind of words you're looking for. In other
words: All words that match your query might not be relevant. Second,
words of
potential interest may be incorrectly tagged so that they don't match a
query they should have matched if they were correctly tagged. In other
words: You might miss out on relevant words. Because of this,
it is always wise to run a couple of test searches, to see how accurate
the hits are, and whether or not your search actually retrieves the
words you
are looking for. Searching for concrete orthographic sequences will on
the
other hand always retrieve the expected
results, and it's therefore
often worthwhile spending some time formulating concrete
queries instead of relying fully on criteria.
There
are different solutions for tagging the transcriptions of the different
languages, cf. the tagging page on the ScanDiaSyn site. This means that while some tags are common for
all languages, there are others that are language specific. In the
following two sections, we'll therefore present non-linguistic and
linguistic criteria separately. Most of the non-linguistic criteria are
general and
language independent, and these can be presented in a
relatively straight-forward manner. The linguistic criteria, on the
other hand,
are to a much greater extent based on language specific tagging. It is
out of scope for
this manual to present all the criteria and their uses in all
languages. The criteria will therefore only be given a quick
presentation
below, and you are encouraged to experiment yourself to find out
precisely
how they are used for the different languages.
Chapter 1 - Contents - Home
1.1.1 The Non-Linguistic Criteria
The Word Criteria
Lemma: The
Norwegian and Danish transcriptions are lemmatized. This means that
it's possible to enter the dictionary form of any Norwegian or Danish
word, select the lemma criterion, and have all word forms of the lemma
included among the hits. Unfortunately, this is presently not possible
for any of the other languages represented in the corpus.
Start
of/within/end of word: These
three criteria are similar in function. They can be combined with an
input in the word box to search for words that begin with, contain or
end with a certain orthographic sequence. The input may also be
phonetic, if combined with the phonetic criterion (see below).
Case
sensitive: When
this criterion is selected, the search is case sensitive. Otherwise, it
is not.
Exclude
word, add (negated) word form and add (negated) lemma: These
five criteria are similar in function in that they all offer different
ways of including or excluding specific word forms or lemmas from the
search. The exclude word criterion simply excludes what you have input
in the word box, while the other criteria let you input multiple word
forms or lemmas and combine these with any other input you may wish to
enter in the word box.
Segment Initial/Final: These
criteria give you the opportunity to search for words that are in the
very
beginning or end of a segment. Since this is a speech corpus, segments
do not necessarily correspond to complete
sentences. Segmentation is rather an attempt to achieve
natural units based on a compromise between turn taking, intonation and
syntax (cf. also section 5).
The
Occurrences Criteria
The
different occurrences criteria (one or more, zero or one and zero
or more) can be used to specify how many times what you've entered in
the linguistic search field can occur in a single hit. In section 1.2 you are presented with the possibility to search
for (multiple) phrases. One of the possible applications of the zero or
one criterion might e.g. be to mark single word boxes in a
search
phrase as optional. Doing so would essentialy yield the same result as
querying for two separate phrases, but is arguably a more streamlined
way of performing the search.
The
Nlex (Non-Lexical) Criteria
These
criteria can be used to search for non-lexical sounds/utterances
in the Norwegian transcriptions (the sibilant criterion is
also used in
Faroese).
The
Descr (Descriptive) Criteria
X: In the Norwegian,
Icelandic and Faroese transcriptions, lexical
words that aren't found in the orthographic standard are marked with an
x-tag. Using this criterion, you will narrow your search to include
only such non-standard lexical words.
O: In
the Norwegian and
Övdalian transcriptions, grammatical words that aren't found
in the orthographic standard are "translated" to their standard
equivalent, and marked with an o-tag. Using this criterion, you will
narrow your search to include only such translated grammatical words.
The
Phonetic Criterion
By
default, any text entered in the word box will be searched for in
the orthographic transcriptions of the recordings in the corpus. The
Norwegian and Övdalian transcriptions
have alternative
transcriptions in addition to the orthographic ones
(for details on the transcriptions, cf. section 2.2.2 below). These transcriptions may be queried using the
phonetic criterion. This may for instance be helpful if you look for
specific
phonetic alternants in Norwegian (cf. the example
searches page).
Chapter 1 - Contents - Home
1.1.2 The Linguistic
Criteria
The
linguistic criteria are either simple or compound criteria. Compound
criteria consist of two or more simple criteria joined by a colon. A
word will normally have been assigned a compound tag because the
automatic tagger hasn't been able to disambiguate it with regard to two
or more
possible tags within a single category (eg. grammatical gender, part of
speech etc.). Words with compound tags won't be included among the
hits if you only search for the simple criteria the compound criterion
consists of. For instance,
searching for the criterion adv won't include words found with the
adv:subjunc criterion. This is worth having in mind when searching for
Norwegian parts of speech.
The
Num (Number) Criteria
These
criteria may be used to
search for words tagged for grammatical number. The criteria sg
(singular) and pl (plural)
are used in all five languages, and sg:pl in all but Icelandic.
The
Case Criteria
These
criteria may be used to search for words tagged for grammatical
case. The
language distribution of the simple gender criteria is shown in
table
1.1.2a below.
| Criterion | Norwegian | Swedish | Danish | Faroese | Icelandic | |
| nom | (nominative) | yes | yes | yes | yes | yes |
| acc | (accusative) | yes | yes | yes | yes | yes |
| gen | (genitive) | yes | no | no | yes | yes |
| dat | (dative) | no | no | no | yes | yes |
| Criterion | Norwegian | Swedish | Danish | Faroese | Icelandic | |
| act | (active) | no | yes | yes | no | yes |
| med | (middle) | no | no | no | no | yes |
| Criterion | Norwegian | Swedish | Danish | Faroese | Icelandic | |
| pres | (present) | yes | yes | yes | yes | yes |
| pret | (preterite) | yes | yes | yes | yes | no |
| past | no | no | no | no | yes | |
| perf-part | (perfect participle) | yes | yes | yes | yes | no |
| Criterion | Norwegian | Swedish | Danish | Faroese | Icelandic | |
| inf | (infinitive) | yes | yes | yes | yes | yes |
| imp | (imperative) | yes | yes | yes | yes | yes |
| ind | (indicative) | no | no | no | yes | yes |
| subjunctive | no | yes | no | no | yes | |
| pres-part | (present participle) | no | yes | yes | yes | yes |
| past-part | (past participle) | no | no | no | no | yes |
| supine | no | yes | no | yes | yes | |
| Criterion | Norwegian | Swedish | Danish | Faroese | Icelandic |
| pause | yes | no | yes | yes | yes |
| unknown | yes | no | no | yes | yes |
| Criterion | Norwegian | Swedish | Danish | Faroese | Icelandic |
| abbrev | yes | no | no | no | no |
| cm-noun | yes | no | no | no | no |
| dem | yes | no | no | yes | yes |
| gov-acc | no | no | no | no | yes |
| gov-dat | no | no | no | no | yes |
| hesit | yes | no | no | yes | no |
| intensifier | yes | no | no | no | no |
| no-case | no | no | no | no | yes |
| pers | yes | no | yes | yes | yes |
| poss | yes | yes | yes | yes | yes |
| prop | yes | yes | yes | yes | yes |
| q | yes | no | no | yes | yes |
| quant | yes | yes | yes | yes | no |
| refl | yes | no | no | yes | yes |
| rel | no | no | no | no | yes |
| strong | no | no | no | no | yes |
| uninflected | no | no | no | no | yes |
| weak | no | no | no | no | yes |
| Criterion | Norwegian | Swedish | Danish | Faroese | Icelandic | |
| masc | (masculine) | yes | yes | yes | yes | yes |
| fem | (feminine) | yes | no | no | yes | yes |
| neut | (neuter) | yes | yes | yes | yes | yes |
| unspec | (unspecified) | no | no | no | no | yes |
Table
1.1.2g - The Gender Criteria
Chapter 1 - Contents - Home
1.2 Searching for
(Multiple) Phrases
Adding
More
Words to a Phrase
More
word boxes may be added or removed by clicking the buttons with plus or
minus signs (cf.
Figure 1.2a). This allows you to
perform phrase searches.
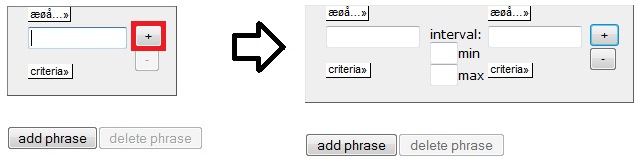
Figure
1.2a - Adding an extra word box
It
is possible to specify the number of words
that may intervene between each query word using the interval function.
The minimum and maximum interval boxes are left empty by default,
restricting
unspecified words from intervening. If the minimum interval is
specified, but not the maximum, unlimited maximum interval is assumed.
Conversely, if the maximum interval is specified, but not the minimum,
a minimum interval of zero is assumed. Setting both the minimum and
maximum interval values
to 1 is equal to having an extra, empty word box between two specified
word
boxes.
Adding
More
Phrases
Using
the add phrase button gives you an extra query row (cf. figure 1.2b
below). You can use this
function to join two or more different queries in
the same result set. The queries will be connected by
disjunction, meaning that you'll get hits matching either
queries. The delete phrase button removes the phrase that
was added last.
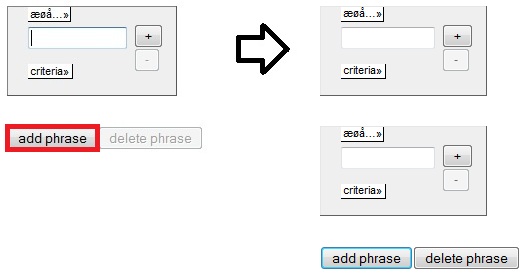
Figure
1.2b - Adding an extra phrase
Chapter 1 - Contents - Home
2 The General Search
Options Field
This
field gives you options that modify the entire search (cf. figure 2).
How to use so
called regular expressions to speed up the input of queries is
explained in section 2.1,
while general options relating to the presentation of the results are
presented in section 2.2.
There we'll look at how we can randomize results, limit the
number of results presented (both total and per page) and select
whether the hit list
should include orthographic and/or phonetic transcriptions.
Remaining
functions are presented in 2.3.

Figure
2 - The General Search Options Field
2.1 Regular
Expressions
Queries
can sometimes be created faster or be made more flexible by typing
regular expressions into the
word box
than by defining a class of words using the criteria
menu (e.g. typing "hus.*" instead of typing "hus" and then selecting the
start of word criterion). Checking the regular expressions box (cf.
figure 2.1)
allows you
to input these expressions in the word box in the linguistic
search field. If this box isn't checked, regular
expressions will be
interpreted as plain text and part of the query.

Figure
2.1 - The Regular Expressions Box
List
of
Alternative Characters
A
list of alternative characters can be
embedded within square
brackets ("[...]"). For
example,
the query "studer[ea]r" will match either
"studerer" or "studerar".
Unspecified
Character
Period (".") represents any character. The query "studer[ea]." will
match "studerer" or "studerar" like above, but also "studerat".
Optionality
Question
mark ("?") indicates that the previous character is optional. If
more than one character are to be indicated as optional, these may be
embedded in parentheses. A list of alternative characters (see above)
may also be indicated as optional using question mark. The query
"studer[ea].?" will
thus match "studerer",
"studerar" and "studerat" like in the example above,
but also "studere" and
"studera". The query "studer(er)?" will match either "studerer" or
"studer", while the query "studer[ea]?" will match either "studer",
"studere" or "studera".
Iteration
Asterisk ("*") indicates that the previous character can occur any
number of times or needn't occur at all. The plus ("+") works in a
similar way, but it requires the preceding character to occur at least
once. Like the case was with question mark above, a string of
more than one character may be embedded within parentheses if the whole
string is to be indicated as iterative. The query "studer.*" will match
"studer" in addition to all words beginning with "studer-", while the
query "studer.+" will only match words beginning with "studer-". The
query "stud(er)+" will match "studer" and "studerer".
It's also possible to limit the maximum (and minimum)
number of iterations using curly brackets ("{...}").
The query "studer.{1,2}"
thus matches all words that start with "studer-" and end with minimum 1
and maximum 2 unspecified characters.
Overriding
Regular
Expressions
If
regular expressions are prefixed by a backslash ("\") they are
interpreted literally when the regular expressions box is checked. The
query "\?" will thus match all occurrences of question mark in the
corpus.
Chapter 2 - Contents - Home
2.2
Result Options
The
result options (cf. figure 2.2) let you adjust how the results are
presented to you on the results page (cf. section 5).
You are given the opportunity to change the number and order of results
retrieved (cf. 2.2.1)
and to change what kind of transcription that is shown on the results
page (cf. 2.2.2).
On the bottom right hand side of the interface, you also find two radio
buttons controlling what type of audio/video player you are presented
with on the results page. Even though this is not part of the general
search options field, it's clearly a result option, and is therefore
dealt with in this section (cf. 2.2.3).
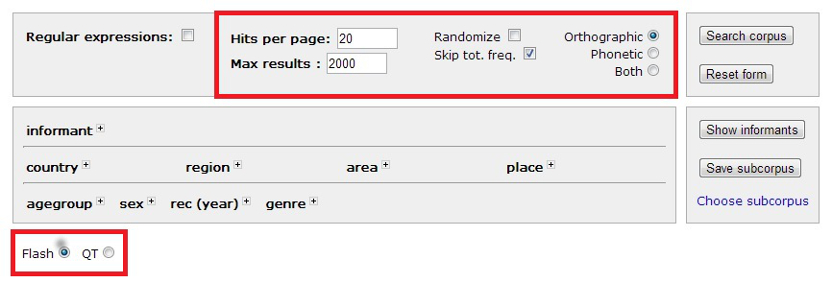
Figure
2.2 - Result Options
Chapter 2 - Contents - Home
2.2.1 Hits per Page,
Max Results, Randomize and Skip Total Frequency
The hits
per page box quite simply
lets you adjust the number of hits shown per result page.
By default, this number is set to 20. The lower this number is, the
faster each results page will load.
The max
results box lets you limit
the total number of hits available
to you in total on the results page. By default, this number is set to
2000. When searching for frequent words or phrases, this number will be
to low to include all matches. In such cases, the max results number
can be adjusted up, but the more matches there are in the corpus, the
slower the results page will load.
The randomize check box is useful in cases where the max results number
is set to a number lower than the actual number of matches your query
has in the corpus. If left unchecked (which is the default), the hits
on the results page will be presented in alphabetical order, based on
the place name (cf. section 3.2).
For words and phrases that are very frequent
then, you will get many hits distributed over the the first few places.
Checking the randomize box will retrieve fewer hits from each place,
and distribute the hits more evenly across all recording locations.
When the max results number is set lower than the total number of hits
a query matches, you can choose whether or not to be presented with the
total number of hits potentially available to you in the corpus using
the skip
total frequency check box. By
default this is checked, hiding
the total number of matches. This is to speed up searches that might
otherwise be slowed down when all potential hits need to be counted.
In figure 2.2.1a below, a results page is shown where the max number,
randomize and skip total frequency options are modified. A search has
been performed for words tagged as verbs (cf. section 1.1.2).
The max results number is set
to 5, which means that the five hits in figure 2.2.1a are all you are
presented with. The skip total frequency box is on the other hand
unchecked, so that we are presented with the total number of words
tagged as verbs in the corpus (440441). The randomize box is checked,
and
this gives us hits from a random selection of recording locations. If
we perform the same search, but with the randomize box left unchecked
(which is the default), we will only get hits from the first recording
location in an alphabetical list (Ål (aal) in Norway), cf.
figure 2.2.1b.
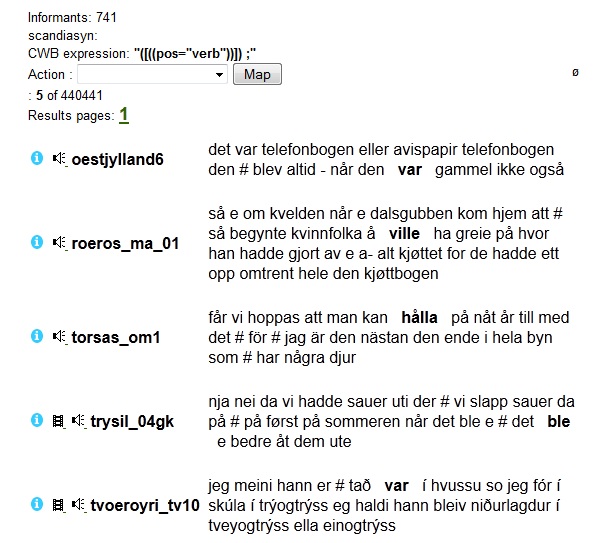
Figure
2.2.1a - Results page where the max number, randomize and skip
total frequency options are modified

Figure
2.2.1b - Results page where max number and skip total frequency
options are modified, but where the randomize box is left unchecked
Chapter 2 - Contents - Home
2.2.2
Orthographic and Phonetic Transcriptions
All
recordings are orthographically transcribed following the standard
of each language. In addition, all Norwegian recordings are transcribed
semi-phonetically, and the Övdalian recordings are transcribed
according to Övdalian orthography. For more details about the
transcriptions themselves, cf. the transcription page on the ScanDiaSyn site. Using the radio buttons named orthographic,
phonetic and both, you can choose which transcriptions to show on the
results
page. The phonetic option includes both the semi-phonetic
Norwegian transcriptions and the Swedish transcriptions with
Övdalian orthography. If the phonetic or both option is
chosen, and the results include other transcriptions than the
previously mentioned ones, the secondary transcription line will be
empty, consisting
only of dashes. This is illustrated in figure 2.2.2, where a query for
verbs (like the one in the last section) returns five random hits from
Norwegian, Övdalian and Danish transcriptions.

Figure
2.2.2 - Results page with
both orthographic and phonetic transcriptions
Chapter 2 - Contents - Home
2.2.3
Changing Audio/Video Player
The
audio/video player selected by default is a Flash player. If there for
some reason seems to be a problem using this, you can select the QT
radio button to use a Quick Time plug in instead. The functions of the
audio/video players are presented in section 5.1.
Chapter 2 - Contents - Home
2.3 Other Functions
The
remaining functions of the general search options field are for
searching the corpus and resetting the form (cf. figure 2.3). As
explained earlier, the
search corpus button opens a new window with the search
results matching your query. The reset form button on the other hand is
used to clean all user
input and reset all fields to default.

Figure
2.3 - The Search Corpus and Reset Form
Buttons
Chapter 2 - Contents - Home
3 The Metadata
Specification Field
The
Metadata Specification Field is shown in figure 3a below. This
field gives you the opportunity to narrow your search based on
sociogeographic variables. The conventions used when giving informants
their code is briefly mentioned in section 3.1.
The informant metadata
categories
(geographic location,
age and sex) are then presented in section 3.2,
while the recording metadata categories (recording year and genre) are
presented in section section 3.3.
Finally, the show informants and subcorpus functions are presented in
section 3.4 and 3.5,
respectively.
In figure 3b, the different
metadata category menus
have been expanded by pressing the + to their right. Variables are
selected by double clicking, which will move them from the left to the
right column. The selected variables are then included in the search by
default, but may also be excluded by selecting exclude from the drop
down menu below the right
hand columns. More
than one selected variable will be connected by conjunction, meaning
that
you'll only get hits on a query matching all selected variables. This
means that when you select more than one variable, you must keep in
mind that there might not be informants or recordings that match them
all, in which case your query will not retrieve any hits. Read more
about how to
avoid this in section 3.2 and 3.4 below.

Figure
3a - The Metadata Specification
Field
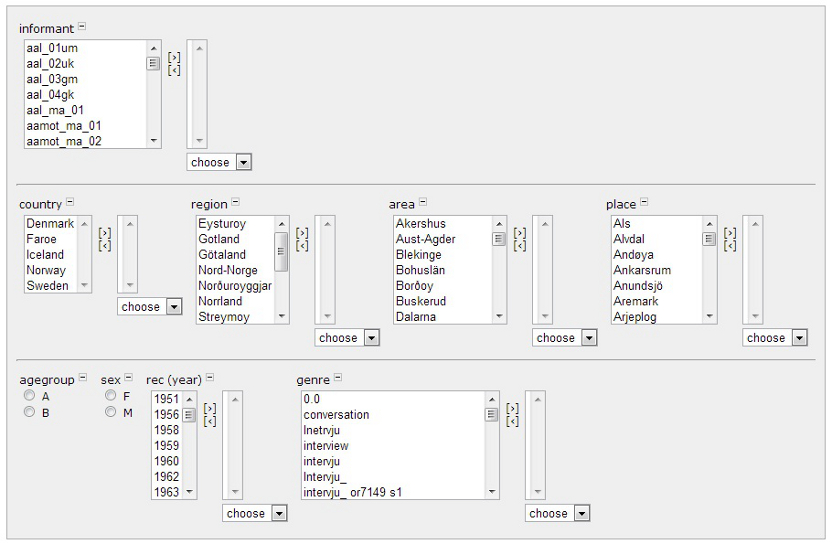
Figure
3b - The Metadata
Specification Field with Expanded
Variables
3.1 Informant
Code Naming Conventions
The
Nordic Dialect Corpus is a collection of recordings done by
different people and at different times, and so the codes given to
informants have also been based on different conventions. Common to all
though, is that the place name is the initial and most central part of
the informant code. All informant codes also contain a number in
addition to the place name, and some
combine the number with one to three letters. In the case of Norwegian
and Swedish informants, these letters may contain info on the sex and
age group of the informant (cf. 3.2).
Old Norwegian recordings form the Oslo Old Dialect Archive (cf. 3.3)
may also be singled out by letters used in the code. The different
letter combinations containing such metadata info are summarized in
table
3.1 below. There are a few other letter combinations also used in
informant codes that do not contain metadata info. These are not
included in the table.
| Letters | Metadata Info |
| um/ym | young man |
| uk/yw | young woman |
| gm/om | old man |
| gk/ow | old woman |
| chi | child |
| ma | Oslo Old Dialect Archive |
Table
3.1 - Informant Code Letters Containing Metadata Information
Chapter 3 - Contents - Home
3.2 The Informant Metadata
Categories
All
informants have various metadata associated with them, and any
search may be narrowed down using three sorts of informant
metadata categories:
geographic location, age and sex. The variables found for
each of these categories are explained in the following.
Geographic
Location
The
category geographic location is divided into four subcategories:
country, region, area and place. These subcategories are used
differently for the different languages. In table 3.2 below, the use of
the region, area and place subcategories in the different languages are
summarized.
| Subcategory | Norwegian | Swedish | Danish | Faroese | Icelandic |
| region | region (landsdel) | region (landsdel) | not used | region (sýsla) or island | region |
| area | county (fylke) | province (landskap) | not used | island or part of island | region |
| place | municipality (kommune) or urban area | municipality (kommun) or urban area | island - but also some Jutish urban areas and regions + Copenhagen | municipality (kommuna) or urban area | municipality or urban area |
Figure
3.2 - Map of Recording Locations
Age
and Sex
The
age category is divided into two
variables, age group A and age
group B. Age group A consists of young people, mainly between 15 and 30
years of age, while age group B consists of adults and elderly people
over 50 years of age. You can read more
about the
distinction on the
NorDiaSyn homepage.
The sex category naturally has the two variables
female (F) and male (M).
Chapter 3 - Contents - Home
3.3 The Recording Metadata Categories
The
recordings themselves also have associated metadata categories:
recording year and genre. These are explained below.
Recording
Year
The
recording years span from 1951 to 2012. The recordings from 1951 to
1984 are old Norwegian recordings from
Målførearkivet (Oslo Old Dialect Archive), which
are meant to complement the modern recordings and give the possibility
for longitudinal studies. The modern ScanDiaSyn recordings are from
1998 to 2012. Exact year spans for each language are given in the list
below:
3.4 The Show Informants
Function
When
you have made a selection of metadata
variables, you may use the
show informants function to show a table presenting all informants that
match your selection. To do this, press the show informants button to
the far right in the metadata specification field (cf. figure 3.4a
below). The list will open in a new window (cf. figure 3.4b below).
Above the table you are given a total word count for all matching
informants, as well as a summary giving you the total number of
matching informants, places and countries. Each individual informant is
then presented in the table along with various informant
metadata given in the different columns. You are also
presented with an individual word count, which specifies the total
number of words included in the corpus for
each informant. You
may sort the contents of each table column alphabetically by
pressing the column header. If your selection of variables doesn't
match any informants, you'll get the
message "Sorry, no data available
on informant.". In this case, you'll need to make a wider selection, or
check for contradicting variables (cf. what's written under the
geographic location heading in section 3.2 above).

Figure
3.4a - The Show Informants Button
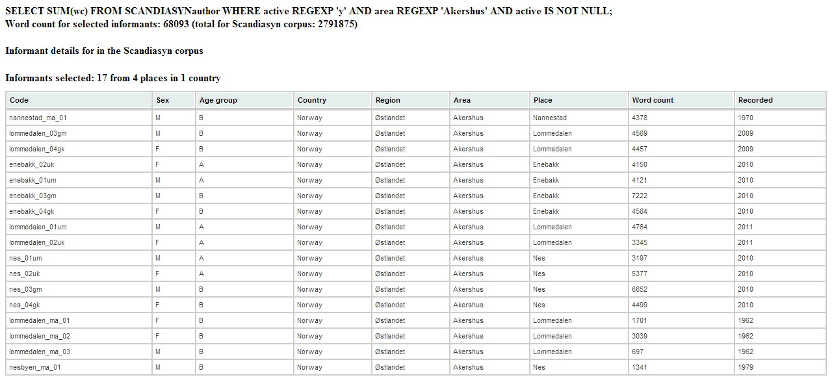
Figure
3.4b - Showing Informants from
Akershus, Norway
Chapter 3 - Contents - Home
3.5 The Subcorpus
Function
The
subcorpus function may be used to save a selection of metadata
variables for later use. This allows you to perform several independent
searches with matching metadata variables without having to reselect
all variables every time. A specific selection of metadata variables is
saved as a subcorpus by pressing the save subcorpus button to the far
left in the metadata specification field (cf. figure 3.5 below). This
will open a new window with a listing of selected variables, and a word
box where you must name your subcorpus. Confirming the name and saving
the subcorpus is then done by pressing the send button to the right of
the word box. When you at a later time want to retrieve a saved
subcorpus, press the choose subcorpus button to the far left in the
metadata specification field (cf. figure 3.5). This will open a list of
saved subcorpora, and the desired subcorpus is selected by clicking on
its name. You will then be directed back to the search interface where
the metadata variables constituting the subcorpus will have been
selected automatically. It is then possible to further modify the
metadata variable selection freely, but any changes that you
want to retrieve at a later time must be saved as a new subcorpus.

Figure
3.5 - The Subcorpus Buttons
Chapter 3 - Contents - Home
4 Other Search Interface
Functions
There
are a few functions available through the search interface in addition
to the ones already discussed. How to manage saved result sets is
described in section 4.1,
while you'll find out how to create and edit
annotation sets in section 4.2.
You may also access complete
transcriptions in HTML-format, this is described in section 4.3.
4.1 Managing
Saved Result
Sets
As
we shall see in section 5.3.7,
Glossa gives you the opportunity to save entire result sets online for
later retrieval. You may manage these sets from the search interface by
clicking the my results button in the top menu, cf. figure 4.1a. This
will take you to the manage saved result sets page, shown in figure
4.1b, where you get the
options to retrieve, delete, rename and copy result sets. The
result sets are personal, and are therefore unique to every
user.
In other words, the result sets shown in the table in figure 4.1b will
not be the
same as the result sets available to you.
Figure
4.1a - Accessing Manage Saved Result
Sets Page
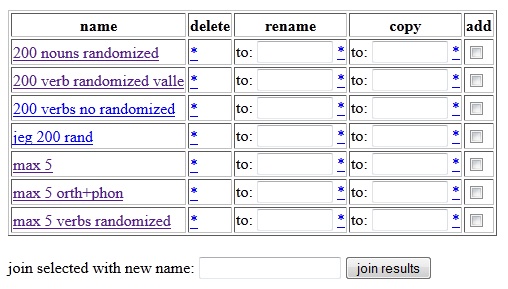
Figure
4.1b - Manage Saved Result Sets Page
Retrieve
a set simply by clicking on its name.
To delete a set, press
the asterisk symbol (*) in the delete column on the same row. Renaming
a set or creating a copy of a set with another name is done by
entering the new name in the rename or the copy column on the
same row, respectively, and pressing the asterisk symbol.
Using the join results function you may merge
two or more
result
sets into a new result set. This is
done by selecting the
result sets you wish to merge (checking the sets in the add column),
entering a name for the new result set in the join selected with new
name word box at the bottom of the page, and pressing the join results
button. The new result set will then appear in the result set list.
Chapter 4 - Contents - Home
4.2 Managing
Annotation Sets
Glossa
gives you the opportunity to annotate
hits both freely and using
predefined sets of values, so called annotation sets. In
section 5.3.5 we will see how to annotate, but for now, we
will
see how to create and edit annotation sets, and how to retrieve
annotation statistics on saved result sets. You may manage your
annotation sets from the search interface by clicking the my
annotations button in the top menu, cf. figure
4.2a below. This will take you to the manage annotation sets page shown
in
figure 4.2b.
Figure
4.2a - Accessing Manage Annotations Page
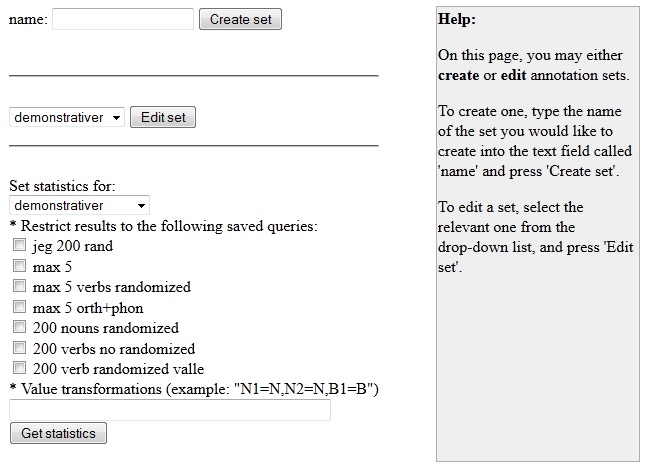
Figure
4.2b - Manage Annotation
Sets Page
Chapter 4 - Contents - Home
4.2.1 Creating and
Editing
Annotation Sets
Creating
a new annotation set is fairly
straight forward: You simply enter a desired name for the annotation
set into the name box on top of the page, and press the create set
button. The set will appear in the drop down menu below, to the left of
the edit set button. The next step is to define values for
the newly created annotation set. Simply find the set you just created
in the drop down menu, and press the edit set button. You will then be
presented with the manage annotation set values page, shown in
figure 4.2.1 below. For each predefined value that you want your set to
contain, enter its name into the name box on top of the page, and press
the add value button. The values will show up in the drop down menu
under the heading "manage existing values" below. To make the
annotation process itself as effortless as
possible, it's also possible to set a default value. This value will be
preselected for all hits, so it might be a good idea setting
the value you expect to be the most frequent as
default (more about the annotation process in section 5.3.5).
To set a value as default, select it from the drop down menu, and press
the set this as default value button.
Because of the way the annotation functionality is designed, all
existing annotation sets are available to all users. Because of this
it's important to name sets so that they are easily recognizable as
your own,
both for yourself and for others. Using your own name or
initials might be a good idea. In addition to this, it's good etiquette
to leave other users' annotation sets alone. Furthermore, it's
unfortunately not possible to delete values from annotation sets at
present.
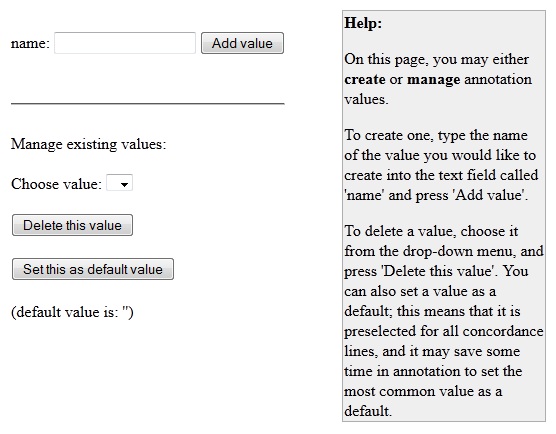
Figure
4.2.1 - Manage Annotation Set Values Page
Chapter 4 - Contents - Home
4.2.2 Retrieving
Annotation
Statistics
for Saved Result Sets
If
you have already annotated some hits, and these are included in one
or more of your saved result sets, you may retrieve annotation
statistics for them directly through the Glossa interface (more on
annotation in section 5.3.5,
and how to save
result sets in section 5.3.7).
Just select the
annotation set you wish statistics for from the drop down menu (cf.
figure 4.2b above), select
the result set(s) that contain the annotated hits you want to include
and then retrieve statistics by clicking the get statistics button. To
illustrate this function we'll retrieve statistics for a saved result
set with 50 random occurrences of the present tense form "er" of the
verb "være (to be)" in the Fredrikstad dialect of Norwegian
(not
included in the saved result sets list in figure
4.2b above). The 50
hits are annotated using the stress annotation set (how this is done is
explained in section 5.3.5).
This is a simple
annotation set containing only two values: stressed and unstressed. The
statistic summary is shown in figure 4.2.2a below.
As mentioned in section 4.1 which dealt with the manage saved result
sets page, saved result sets are user specific. A different
list containing your own result
sets will therefore be visible to you on the manage annotation sets
page shown in figure
4.2b.
Using
the value transformations box you may rename and/or merge values
in annotation sets when you are retrieving statistics. As shown in the
example
on the page, renaming is done after the following pattern (without the
quotation marks): "old_value_name=new_value_name". If you want to merge
two or more values into one new value, you simply give them the same
new value name (and separate them using a comma and no space):
"old_value_name_1=new_value_name_1,old_value_name_2=new_value_name_1".
To illustrate the renaming of values, let's say you want to translate
the unstressed and stressed values into Norwegian. You will then need
to input the following in the value transformations box:
"unstressed=trykksvak,stressed=trykksterk". The statistics summary this
gives is shown in figure 4.2.2b below.
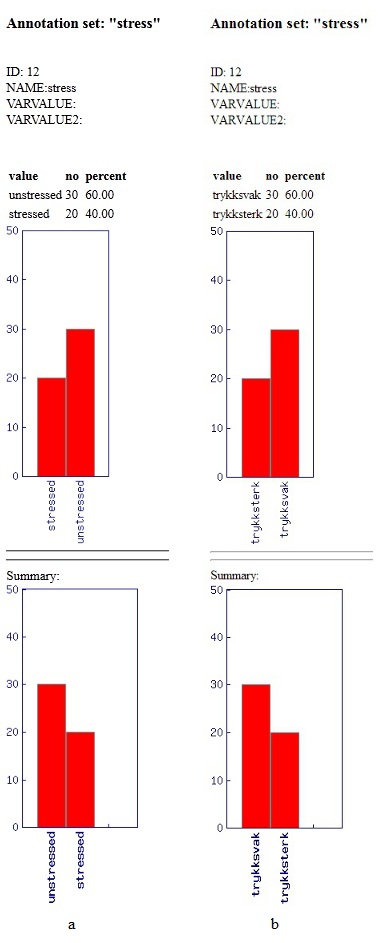
Figure
4.2.2 - Statistic Summaries
Chapter 4 - Contents - Home
4.3 Accessing Complete
Transcriptions
in HTML-format
Complete
transcriptions for all recordings are available for download
via the link marked out in red in figure 4.3 below. For the Norwegian
and Övdalian recordings only the phonetic transcriptions are
available here
(i.e. Norwegian transcriptions that are
semi-phonetic and Övdalian transcriptions that are transcribed
using the local orthography).
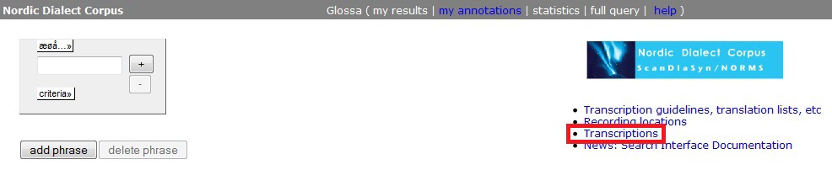
Figure
4.3a - Accessing Complete Transcriptions
Chapter 4 - Contents - Home
4.4 Bug and Error Report
On
the bottom of the search interface page, you'll find a link to a
feedback form. We'd be greatful if you use this to report any bugs or
errors that you might find in the corpus, or any other feedback you
might have.
Chapter 4 - Contents - Home
5 The Results Page
The
search results always open in a new window like the one presented in figure
2.2.1a, here reproduced as
figure 5 below. After giving a quick
overview of the page, the following sections will deal with various
functions available through the results page in more detail.
At the very top of the results page, you'll find the number of
informants included in the search, which in turn is followed by
the CWB search expression. Below the action drop down menu (cf. 5.3)
and the
map button (cf. 5.2),
you'll
see how many hits that are available to you and how many hits there are
in total in the entire corpus (see also section 2.2.1).
A list of results pages follows, with the current page shown in bold
(in figure 5 there is only one result page in total). The rest of the
results page contain the hits themselves. Each
hit is presented in the form of a segment containing the
word (or phrase) searched for, which in turn is in bold types.
Segment division is done as part of the transcription, and an optimal
segment is the same as an utterance or a meaningful unit with regard to
both syntactical and intonational boundaries. In spoken language, such
optimal segments are however the exception rather than the rule, and
most often the segment division is a compromise between multiple
criteria. The code of the informant having uttered the segment is in
the left
column, and here you also find three clickable buttons. The first one ( )
opens informant metadata in a new window. The two following buttons (
)
opens informant metadata in a new window. The two following buttons ( and
and 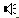 ) open video and audio
or just audio for the segment in a media player (cf. 5.1)
on
top of the results page. As
is shown in Figure 5, not all recordings include video, and in most
such
cases there will just be an audio button available. In a few cases both
media buttons will be available even though the only available media is
audio.
Because of this, you should try the audio button as well if you
experience lack of video.
In cases where neither of the media buttons work, please report it in
as a
bug (cf. 4.4)!
) open video and audio
or just audio for the segment in a media player (cf. 5.1)
on
top of the results page. As
is shown in Figure 5, not all recordings include video, and in most
such
cases there will just be an audio button available. In a few cases both
media buttons will be available even though the only available media is
audio.
Because of this, you should try the audio button as well if you
experience lack of video.
In cases where neither of the media buttons work, please report it in
as a
bug (cf. 4.4)!
Figure
5 - The
Results Page
5.1
The Media Player
As
mentioned in section 2.2.3, both a Flash player and a QuickTime player
are available to the user. The Flash player is selected by default, and
will
be the player that is presented in the following, but the QuickTime
player offers the
same
functionality as the Flash player.
When clicking the video () or audio ()
button to the left of
a hit, the media player will open in the top of the results page, cf.
figure 5.1a. The segment currently playing is highlighted in orange on
the right hand side. The recording starts automatically. To pause the
recording, or play it again without reloading, simply press anywhere in
the video window. Pressing the play button below the video will reload
and restart the recording. The media player also allows you to broaden
the context of any
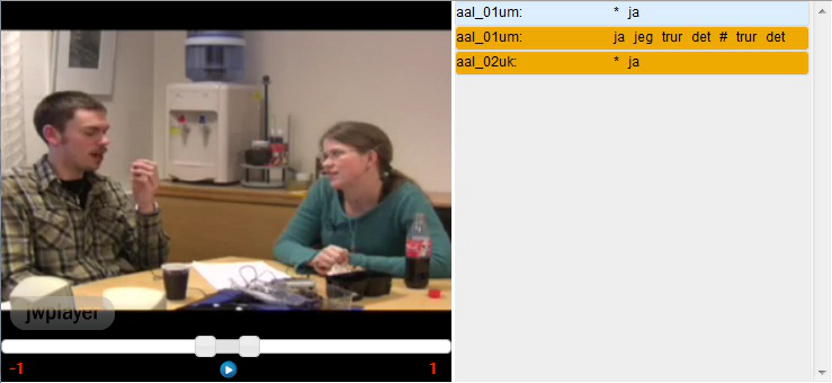
hit using the sliders directly above the play button. In figure 5.1b,
the left context has been adjusted to include the three preceding
segments.
Figure
5.1a - The Media Player
Figure
5.1b - The Media Player with Expanded Context
Chapter 5 - Contents - Home
5.2
The Map Function
Basically,
this function lets you see your hits on a map. When the search is done
in recordings that have both an orthographic and a phonetic
transcription (cf. 2.2.2),
you are also shown variation in the phonetic transcriptions (if you
search for a multi-word phrase, variations are only shown for the first
word). For Norwegian transcriptions that are transcribed both
orthographically and semi-phonetically then, this is a good way to look
for phonetic variation.
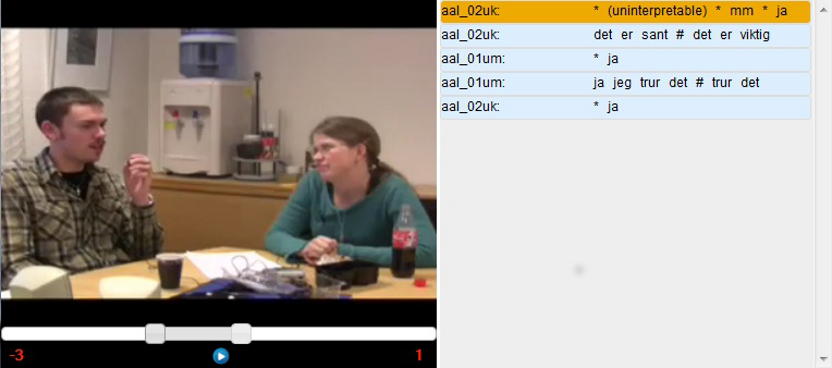
Let's say we are interested in phonetic variation in the first person
pronoun in Eastern Norwegian dialects. We perform a search for the word
form "jeg", adjusting the maximum number of hits up to 20000 (to be
sure to include all hits) and narrowing the search to the
Østlandet region (cf. 2.2.1 and 3.2).
If we then press the map button next to the action drop down
menu on top of the results page, we'll be presented with a map like the
one in figure 5.2a below. The recording locations from which
the search has returned hits
are shown as red dots on the map, and the different phonetic
realizations are shown in a list to the right. By selecting a color
each phonetic realization may be marked out on the map. To illustrate
this, the recording locations where we find the phonetic realization
"i" is marked out with
red in figure 5.2b.
Figure
5.2a - Hit Map
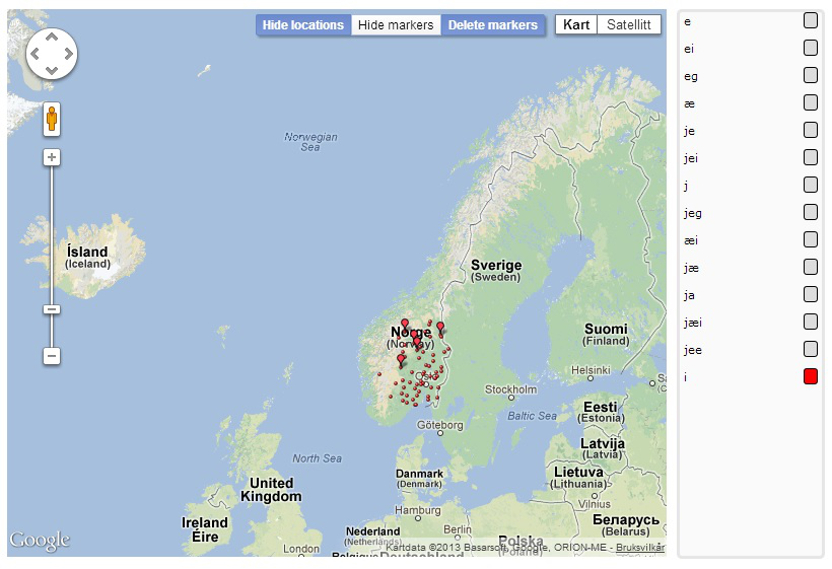
Figure
5.2b - Hit Map with Marked Forms
Chapter 5 - Contents - Home
5.3
The Action Menu
There
are several functions available for handling the results available
through the action drop down menu.
You may count match occurrences (5.3.1), download hits (5.3.2), sort hits (5.3.3),
compile statistics on collocations (5.3.4), annotate hits
(5.3.5), delete
hits from the hit list (5.3.6)
or save
hits for later
retrieval (5.3.7).
Chapter 5 - Contents - Home
5.3.1 Count
The
count function easily allows you to get an overview over how many times
each specific match to your query occurs in the hit list. When
count is selected in the action
drop down menu, the options in figure 5.3.1a will appear. The different
options are presented in the following.
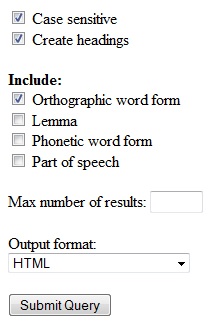
Figure
5.3.1a - Count
Options
The
case sensitive option is selected by default, making hits that only
differ in case are counted separately. Deselect this, and such hits are
counted together. The create headings option applies to the
downloadable output formats, which are dealt with in 5.3.2.
You are also given the option to choose what level of accuracy that should be included in the count.
The more specific level orthographic word
form is
what is selected by default. When only
this level of accuracy is selected, all hits that include different
orthographic word forms
will be counted separately. The most general level is part of speech.
When only this level of accuracy is selected, all hits that include
different parts of speech will be counted separately. At a slightly
less
general level comes lemma.
It is
only available for
transcriptions that are lemmatized, i.e. Norwegian and Danish, cf. 1.1.1.
When only this level of accuracy is selected, all hits that include
different lemmas
will be counted separately.
The most accurate level, phonetic
word form, is only
available for transcriptions
that have a phonetic transcription, i.e. Norwegian and
Övdalian, cf. 2.2.2.
When only this level of accuracy is selected, all hits that
include different phonetic word forms
will be counted
separately. This is handy for quantifying phonetic variation in
Norwegian transcriptions, cf. the example below.
More than one level of accuracy may be included in the count, but the
hits will always be grouped
according to the most accurate level selected. In the output lists (see
below), the different levels will be presented in the following order
for each hit (separated by a hyphen): orthographic word
form - lemma - phonetic word form - part of speech.
The maximum number of results is left empty by default, which means
that all hits are included in the count. Any number entered here will
limit the number of unique hits included in the count, regardless of
how many matches each of these hits includes.
The
count results may be output in several different formats. HTML is what
is selected by default, and will quite simply produce a
list of the number of occurrences of each unique hit, with the most
frequent hit at the top. The histogram and pie chart outputs give a
graphic representation of the same values.
The tab-separated values,
comma-separated values and excel spreadsheet
output formats are all primarily for downloading results for later
reference. Tab and
comma separated values may be saved as text files and imported in
various database software.
To
illustrate the use of the count function, we can use it on the results
for the
search for phonetic variation in the first person singular personal
pronoun "jeg" in Eastern Norwegian presented in 5.2.
All hits in this search
belong to
the same lemma
and orthographic word form, so what we are interested in is
the phonetic word form. We therefore select phonetic word form
as
accuracy
level for the counting, and at the same time deselect orthographic word
form. The
rest of the options are left in their default settings, before we press
the submit query button. The list of the different phonetic
realizations we then are presented with is reproduced in figure 5.3.1b
below.

Figure
5.3.1b - Count List for Phonetic
Realizations of "jeg" in Eastern Norwegian
Chapter 5 - Contents - Home
5.3.2 Download
The
download function gives you the opportunity to save the hits locally on
your computer. In addition to the match phrase itself, the left and
right context will always be included, and you can optionally include
informant code, recording genre and informant word count. When download
is selected in
the
action
drop down menu, the options in figure 5.3.2a will appear. The different
options are presented in the following.
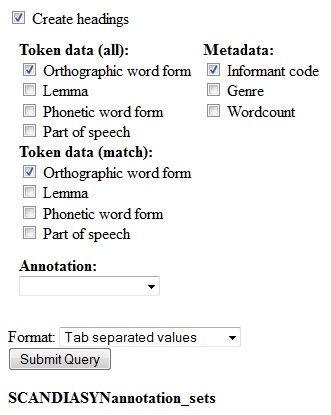
Figure
5.3.2a - Download Options
The
create headings box is checked by default,
ensuring that the
different data columns all have headings that specify their contents
(which may be informant code, genre, word count, left context,
match or right context). Such headings will not be created if this box
is unchecked.
The check boxes found under the token data headings gives you the
opportunity to include different levels of accuracy of the hits you
download. The different levels of accuracy are orthographic word form
(selected by
default), lemma,
phonetic
word form and part of speech. The
different
levels of accuracy are described in more detail in section 5.3.1 above, note in particular that the levels lemma and phonetic
word form only are available for certain languages (Norwegian and
Danish, and Norwegian and Övdalian, respectively). The
selections
made under
token
data (all) apply to the left and right
context, in addition to the match itself, and override any selections
made under token data (match).
When
downloading results, it is also possible
to include three kinds of
metadata associated with each hit: informant code (cf. 3.1),
genre (cf. 3.3),
and word count. The word count
specifies the total number of words included in the corpus for each
informant (cf. also 3.4).
Annotations (cf. 4.2 and 5.3.5)
connected to hits may also be included in the download,
but values may only be downloaded
from one set of annotations at the time (or free
annotation values). Simply select the annotation set with the values
you wish
to include from the annotation drop down menu.
The following formats are available for download: tab separated values
(default), comma separated values, Excel spreadsheet and HTML.
Chapter 5 - Contents - Home
5.3.3 Sort
The
sort function gives you the opportunity to arrange the hits on the
result page in a specific order. When sort is selected in
the
action
drop down menu, the options in figure 5.3.3 will appear. The different
options are presented in the following.
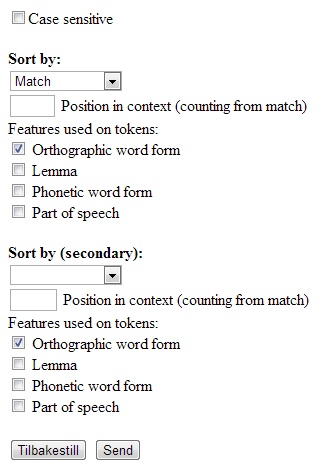
Figure
5.3.3 - Sort Options
The
case sensitive box is unchecked by default,
meaning that hits will
be sorted alphabetically irrespective of capitalization.
You may sort your hits alphabetically after
left context, match or right context. In addition you may sort your
hits after informant code (which is also the default sorting), or
simply randomize your hits.
If you wish to sort your hits alphabetically after match or left or
right context, you also need to select what level of accuracy the hits
should be sorted after ("features used on tokens"). The default
selection
is orthographic word form. As mentioned in section 5.3.1,
two of the other levels are only available for some languages: lemma
for Danish and Norwegian, and phonetic word form for Övdalian
and
Norwegian.
If
you choose to sort after one of the
context variables, you also need to specify which position in the
context the word you wish to sort your hits after should have. If this
field is left empty, the hits are sorted after the first word to the
left/right of the match.
If
you wish, you may have secondary sorting of your hits in addition to
the primary sorting. This means that your
hits will be sorted after your primary sorting options first, and then
sorted after
the secondary sorting options for hits that are identical
according to the primary ones.
Even
though more than one
level of accuracy may be chosen, this should be avoided due to
unpredictable sorting results. It's better to use secondary sorting,
which achieves the same goal in a more predictable manner. An
unfortunate bug that should also be noted is that sorting
results resets
any choices made in the result options (cf. section 2.2
above) to their default values. If you have selected to show both
orthographic and phonetic transcriptions, though, the phonetic
transcriptions will reappear if you try to change the result page.
Chapter 5 - Contents - Home
5.3.4 Collocations
Using
the collocations option in the action
menu, you may compile statistics on collocations with one or two
words in addition to the match of your search (so called bigrams and
trigrams). When collocations is
selected in
the
action
drop down menu, the options in figure 5.3.4a will appear. Some of these
are presented in the following, but explaining the different
statistical measures
are unfortunately out of scope for this user
manual. Note also that only the first word in a matching phrase is
used, so if any matching phrase contains more than one word, the right
side statistics will contain errors.
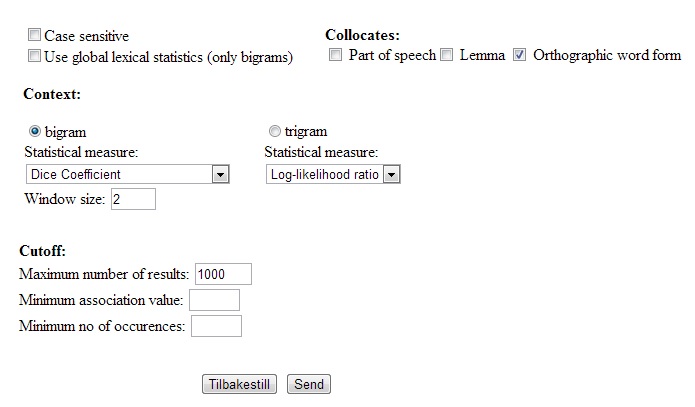
Figure
5.3.4a - Collocations Options
The
case sensitive box is left unchecked by default. This means that
bigrams and trigrams that include words that are identical apart from
capitalization will be counted together. If you want such collocations
to be counted separately, check this box.
The
collocates option lets you choose what the match should be
collocated with. There are three levels of accuracy (cf. section 5.3.1)
to choose from: orthographic word form, lemma and
part of speech. The default
selection gives you bigrams or trigrams where the match is collocated
with orthographic word
forms.
You may also collocate your match with parts
of speech or lemmas (but
the latter only works for transcriptions of Norwegian and Danish that
are lemmatized).
More than one level of accuracy may be chosen, but the collocation will
always follow the most accurate level selected. In the output lists
then, the more general levels will just serve as information
(to
what lemma a word form belongs, or to what part of speech a word form
or lemma belongs).
If
you aren't interested in the more marginal collocations, you may
also set different cutoff values. The maximum number of results value
is set to 1000 by default. This means that you will only be presented
with the 1000 most frequent collocations. The minimum association value
field is left empty by default, and has to do with the results of the
statistical measures. The minimum number of occurrences field is also
left empty by default, but you may enter any number here in order to
only retrieve collocations that have a minimum number of occurrences in
the current result set.
To
exemplify the use of the collocations option, we perform a
search for all occurrences of the 1st person sg. pronoun "jeg" in
Norwegian. The aim is to see what the 5 most frequent parts of speech
to the left and right of "jeg" are. To do this, we select the
collocations option from the action menu of the results page, and then
select only "part of speech" of the collocates options, and the
statistical
measure "frequency" under bigram. The rest of the options are left in
their default settings. When we click the submit query button, we then
get the results shown in figure 5.3.4b. The left context is shown in
the left column and the right context in the right column. The first
subcolumn shows the ngram, or collocation, and the numbers under "occ"
show the number of occurrences in the result set. You may download the
results using the drop down menu on the top of the page. The following
formats are available: tab separated values, comma separated values and
Excel spreadsheet. Unfortunately, the histogram output formats do not
work at present.
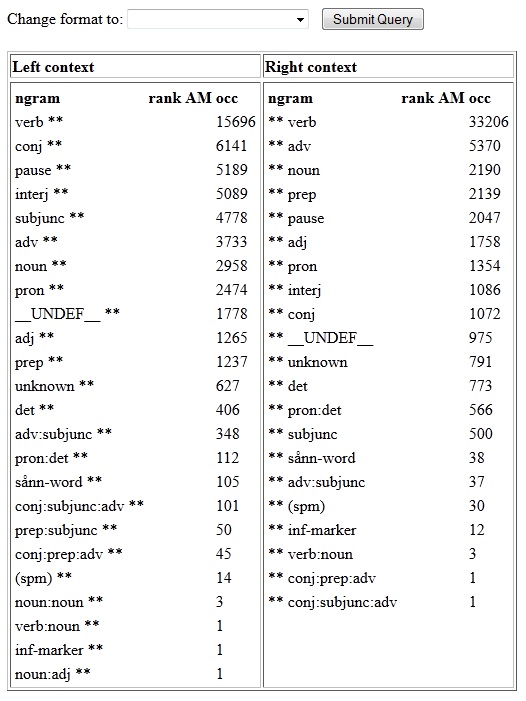
Figure
5.3.4b - Collocation Frequencies
Chapter 5 - Contents - Home
5.3.5 Annotate
Glossa
gives you the opportunity to annotate
hits both freely and using
predefined sets of values, so called annotation sets. In
section 4.2 we saw how to create and edit
annotation
sets, and how to retrieve
annotation statistics on saved result sets. In this section however,
we'll learn
how to perform the annotation
itself. When you select the annotate option from the action drop down
menu, you are presented with the annotate options presented in figure
5.3.5a below.
If you already have created an annotation set, you may simply select it
from the drop down menu and press the annotate button. If not, you may
go to the manage annotation sets page following the manage
sets
link.
Since this process is thoroughly explained in section 4.2.1,
we won't repeat it here, and we jump straight to explaining annotating
using an existing annotation set. An alternative to using an annotation
set is free annotation. This is also explained below.
It is important to remember that annotations are not retrievable
independently of the hits annotated. It's therefore important to
remember your query, or quite simply save the hits you want to
annotate.
How to save hits is explained in section 5.3.7.
As mentioned in section 4.2.1,
all
existing annotation sets are available to all users because of the way
the annotation
functionality is designed. This also means that a certain
segment (cf. section 5)
may only be annotated once
using a certain annotation set (or
free annotation). It's therefore good etiquette
to leave other users' annotation sets alone, even if there already
exists one that fits your needs, and rather make a new one for your own
use. The same applies if someone else already has saved free annotation
for a segment: You may add your own annotation, but add it onto the
annotation that's already there using your own initials or some other
way of identifying that part of the annotation is yours.
Figure
5.3.5a - Annotate Options
Annotating
Using an Existing Annotation Set
To
illustrate how to annotate hits using an existing annotation set, we
have performed a search for the
present tense form of the verb "være", "er", in the
Fredrikstad dialect of Norwegian (cf. 3.2).
We have limited our
maximum
number of hits to 50, and have made sure the hits are randomized
(cf. 2.2.1).
We have also saved the results (cf. 5.3.7)
to be able to retrieve them later
(along with the
annotations). Following the guidelines in section 4.2.1,
we have prepared an annotation set called "stress", with the values
"stressed" and "unstressed". Using this set, we can listen through the
50 hits and easily annotate stress variation. When we select
the stress set from the annotate options drop down menu (cf. figure
5.3.5a above), we will
be presented with the hit list, now with a small drop down menu
above each hit containing the predefined values from the annotation set
(cf. figure 5.3.5b below). The value "unstressed" is set as the
default, and is therefore preselected for all hits. Now we may simply
listen through the hits one by one, changing the value in the drop down
menu from "unstressed" to "stressed" if need be, until we have done so
for all the hits on result page 1. It's now very important that we
press the save annotations button before we continue on to page two. If
we change pages without saving, our annotations will be lost! When the
save annotations button is pressed, you'll be redirected to a page
confirming your annotations. To get back to the result page, you may
just use the back button in your browser. The annotations may
later be downloaded along with the hits (cf. section 5.3.2)
or summarized statistically through the Glossa interface (cf. section 4.2.2).
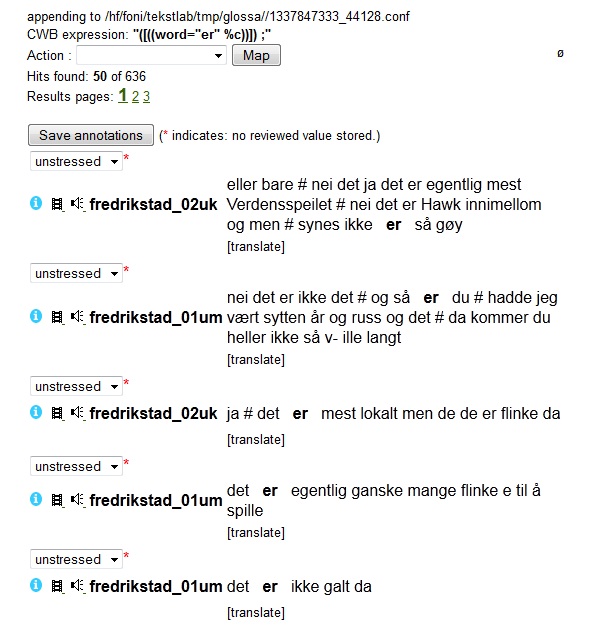
Figure
5.3.5b - Annotating Hits
Free
Annotation
Annotating
hits with more unsystematic notes is
possible using free
annotation. When this option is selected from the annotate options drop
down menu
(cf. figure 5.3.5a above), we are presented with a hit list
with a text box above each hit. Any text may be entered into these
boxes, and as with annotation using sets explained above, this
must be saved using the save annotation button before changing result
page. The annotations may later be downloaded along with the hits (cf.
section 5.3.2).
Chapter 5 - Contents - Home
5.3.6 Delete Hits
This
function allows you to delete single hits
from a set of results. When delete
hits is selected from
the
action
drop down menu, each hit will be preceded by a check box, and you'll be
given the following options: delete selection, select all, unselect all
and finished deleting, cf. figure 5.3.6. You delete hits by checking
their box and pressing the delete selection button. You will then be
asked if you are finished deleting hits, or if you want to delete more
hits on the same page. When you are finished, the result set
may be
saved as usual, cf. section 5.3.7.
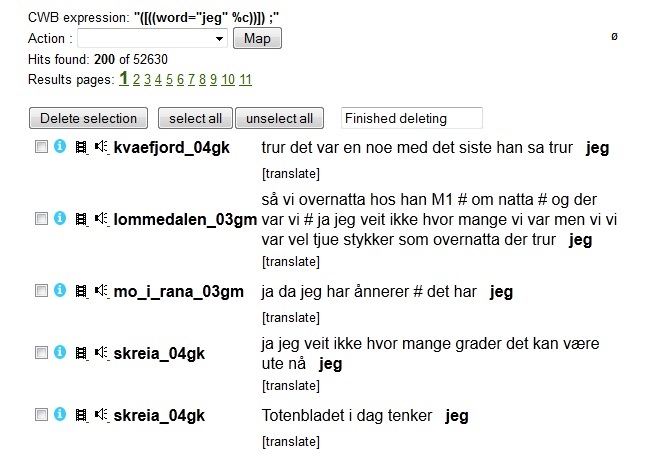
Figure
5.3.6 - Deleting Hits
Chapter 5 - Contents - Home
5.3.7 Save Hits
You
may also save
a result set through the action menu for later retrieval.
When you select the save hits
option from the action drop down
menu, you are presented with the save hits options page presented in
figure
5.3.7 below. Here, you simply enter the desired name of your result
set, and press the save results button. Previously used names are
listed below and cannot be reused.
Retrieving
and editing saved result sets may be done through the search
interface, cf. section 4.1.
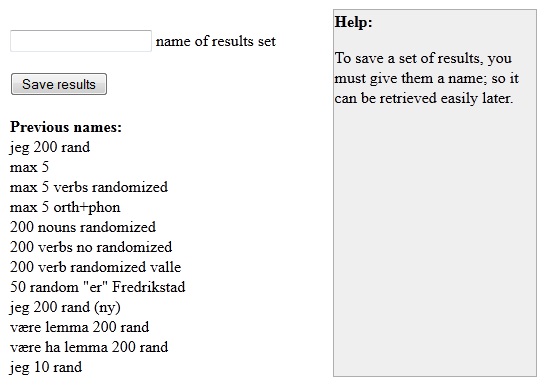
Figure
5.3.7 - Save Hits Options
Chapter 5 - Contents - Home